Beyond Capable: Accuracy, Calibration, and Robustness in Large Language Models


PUBLISHED IN
Artificial Intelligence EngineeringAs commercial and government entities seek to harness the potential of LLMs, they must proceed carefully. As expressed in a recent memo released by the Executive Office of the President, we must “…seize the opportunities artificial intelligence (AI) presents while managing its risks.” To adhere to this guidance, organizations must first be able to obtain valid and reliable measurements of LLM system performance.
At the SEI, we have been developing approaches to provide assurances about the safety and security of AI in safety-critical military systems. In this post, we present a holistic approach to LLM evaluation that goes beyond accuracy. Please see Table 1 below. As explained below, for an LLM system to be useful, it must be accurate—though this concept may be poorly defined for certain AI systems. However, for it to be safe, it must also be calibrated and robust. Our approach to LLM evaluation is relevant to any organization seeking to responsibly harness the potential of LLMs.

Holistic Evaluations of LLMs
LLMs are versatile systems capable of performing a wide variety of tasks in diverse contexts. The extensive range of potential applications makes evaluating LLMs more challenging compared to other types of machine learning (ML) systems. For instance, a computer vision application might have a specific task, like diagnosing radiological images, while an LLM application can answer general knowledge questions, describe images, and debug computer code.
To address this challenge, researchers have introduced the concept of holistic evaluations, which consist of sets of tests that reflect the diverse capabilities of LLMs. A recent example is the Holistic Evaluation of Language Models, or HELM. HELM, developed at Stanford by Liang et al., includes seven quantitative measures to assess LLM performance. HELM’s metrics can be grouped into three categories: resource requirements (efficiency), alignment (fairness, bias and stereotypes, and toxicity), and capability (accuracy, calibration, and robustness). In this post, we focus on the final metrics category, capability.
Capability Assessments
Accuracy
Liang et al. give a detailed description of LLM accuracy for the HELM framework:
Accuracy is the most widely studied and habitually evaluated property in AI. Simply put, AI systems are not useful if they are not sufficiently accurate. Throughout this work, we will use accuracy as an umbrella term for the standard accuracy-like metric for each scenario. This refers to the exact-match accuracy in text classification, the F1 score for word overlap in question answering, the MRR and NDCG scores for information retrieval, and the ROUGE score for summarization, among others... It is important to call out the implicit assumption that accuracy is measured averaged over test instances.
This definition highlights three characteristics of accuracy. First, the minimum acceptable level of accuracy depends on the stakes of the task. For instance, the level of accuracy needed for safety-critical applications, such as weapon systems, is much higher than for routine administrative functions. In cases where model errors occur, the impact may be mitigated by retaining or enhancing human oversight. Hence, while accuracy is a characteristic of the LLM, the required level of accuracy is determined by the task and the nature and level of human involvement.
Second, accuracy is measured in problem-specific ways. The accuracy of the same LLM may vary depending on whether it is answering questions, summarizing text, or categorizing documents. Consequently, an LLM’s performance is better represented by a collection of accuracy metrics rather than a single value. For example, an LLM such as LLAMA-7B can be evaluated using exact match accuracy for factual questions about threat capabilities, ROUGE for summarizing intelligence documents, or expert review for generating scenarios. These metrics range from automatic and objective (exact match), to manual and subjective (expert review). This implies that an LLM can be accurate enough for certain tasks but fall short for others. Additionally, it implies that accuracy is illy defined for many of the tasks that LLMs may be used for.
Third, the LLM’s accuracy depends on the specific input. Typically, accuracy is reported as the average across all examples used during testing, which can mask performance variations in specific types of questions. For example, an LLM designed for question answering might show high accuracy in queries about adversary air tactics, techniques, and procedures (TTPs), but lower accuracy in queries about multi-domain operations. Therefore, global accuracy may obscure the types of questions that are likely to cause the LLM to make mistakes.
Calibration
The HELM framework also has a comprehensive definition of calibration:
When machine learning models are integrated into broader systems, it is critical for these models to be simultaneously accurate and able to express their uncertainty. Calibration and appropriate expression of model uncertainty is especially critical for systems to be viable in high-stakes settings, including those where models inform decision making, which we increasingly see for language technology as its scope broadens. For example, if a model is uncertain in its predictions, a system designer could intervene by having a human perform the task instead to avoid a potential error.
This concept of calibration is characterized by two features. First, calibration is separate from accuracy. An accurate model can be poorly calibrated, meaning it typically responds correctly, but it fails to indicate low confidence when it is likely to be incorrect. Second, calibration can enhance safety. Given that a model is unlikely to always be right, the ability to signal uncertainty can allow a human to intervene, potentially avoiding errors.
A third aspect of calibration, not directly stated in this definition, is that the model can express its level of certainty at all. In general, confidence elicitation can draw on white-box or black-box approaches. White-box approaches are based on the strength of evidence, or likelihood, of each word that the model selects. Black-box approaches involve asking the model how certain it is (i.e., prompting) or observing its variability when given the same question multiple times (i.e., sampling). As compared to accuracy metrics, calibration metrics are not as standardized or widely used.
Robustness
Liang et al. offer a nuanced definition of robustness:
When deployed in practice, models are confronted with the complexities of the open world (e.g. typos) that cause most current systems to significantly degrade. Thus, in order to better capture the performance of these models in practice, we need to expand our evaluation beyond the exact instances contained in our scenarios. Towards this goal, we measure the robustness of different models by evaluating them on transformations of an instance. That is, given a set of transformations for a given instance, we measure the worst-case performance of a model across these transformations. Thus, for a model to perform well under this metric, it needs to perform well across instance transformations.
This definition highlights three aspects of robustness. First, when models are deployed in real-world settings, they encounter things that were not included in controlled test settings. For example, humans may enter prompts that contain typos, grammatical errors, and new acronyms and abbreviations.
Second, these subtle changes can significantly degrade a model's performance. LLMs do not process text like humans do. As a result, what might appear as minor or trivial changes in text can substantially reduce a model’s accuracy.
Third, robustness should establish a lower bound on the model’s worst-case performance. This is meaningful alongside accuracy. If two models are equally accurate, the one that performs better in worst-case conditions is more robust.
Liang et al.’s definition primarily addresses prompt robustness, which is the ability of a model to handle noisy inputs. However, additional dimensions of robustness are also important, especially in the context of safety and reliability:
- Out-of-distribution robustness refers to a model’s ability to handle new subjects. For example, inputs from domains not included in data used for training.
- Task robustness refers to whether an LLM, intended for one task, can maintain a high level of performance when applied to different tasks.
- Adversarial robustness is concerned with a model’s ability to withstand attempts by intelligent adversaries to manipulate or degrade its performance. In many scenarios, particularly in security-sensitive areas, models may face deliberate attempts to trick or confuse them. Adversarial robustness ensures that the model remains reliable and accurate even in the face of such attacks.
Implications of Accuracy, Calibration, and Robustness for LLM Safety
As noted, accuracy is widely used to assess model performance, due to its clear interpretation and connection to the goal of creating systems that respond correctly. However, accuracy does not provide a complete picture.
Assuming a model meets the minimum standard for accuracy, the additional dimensions of calibration and robustness can be arranged to create a two-by-two grid as illustrated in the figure below. The figure is based on capability metrics from the HELM framework, and it illustrates the tradeoffs and design decisions that exist at their intersections.
Models lacking both calibration and robustness are high-risk and are generally unsuitable for safe deployment. Conversely, models that exhibit both calibration and robustness are ideal, posing lowest risk. The grid also contains two intermediate scenarios—models that are robust but not calibrated and models that are calibrated but not robust. These represent moderate risk and necessitate a more nuanced approach for safe deployment.
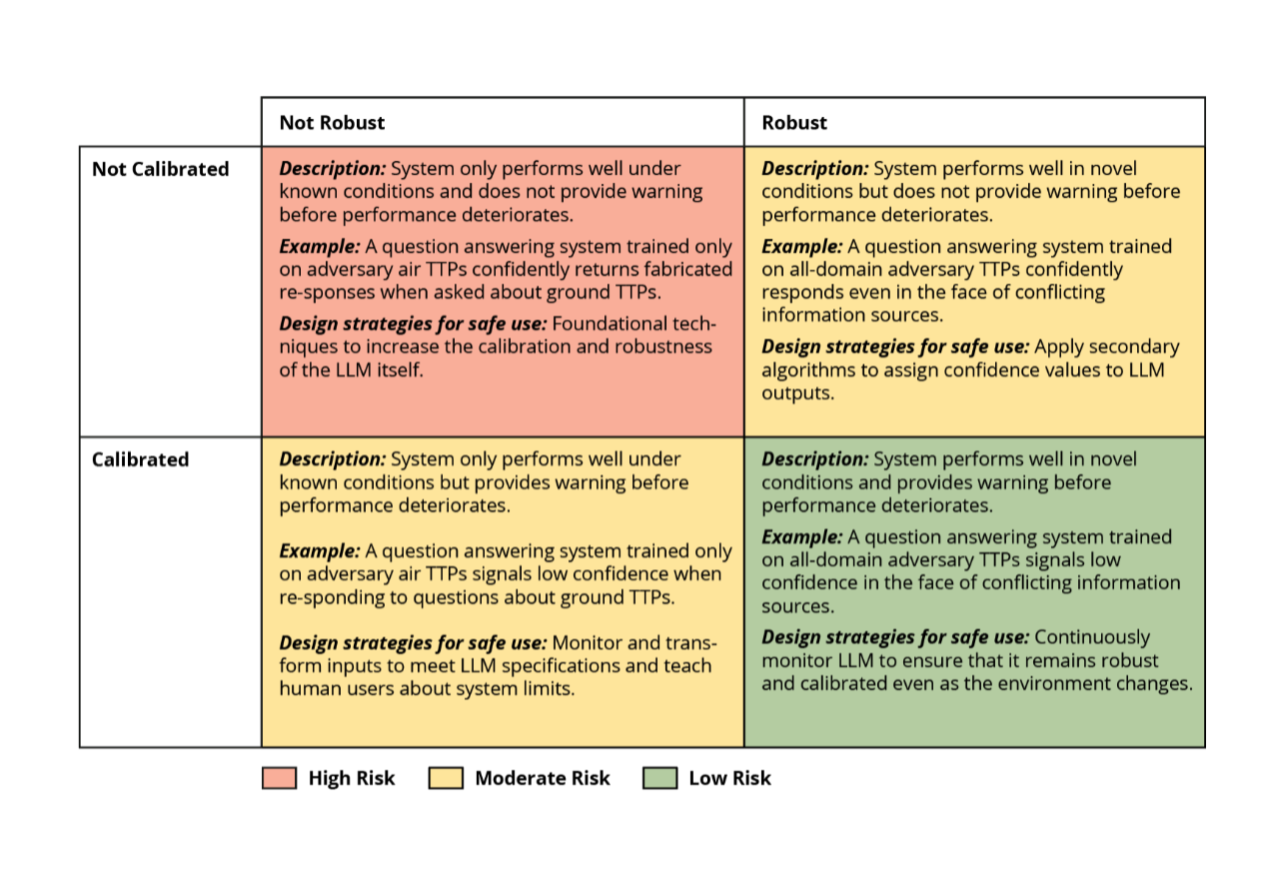
Task Considerations for Use
Task characteristics and context determine whether the LLM system that is performing the task must be robust, calibrated, or both. Tasks with unpredictable and unexpected inputs require a robust LLM. An example is monitoring social media to flag posts reporting significant military activities. The LLM must be able to handle extensive text variations across social media posts. Compared to traditional software systems—and even other types of AI—inputs to LLMs tend to be more unpredictable. As a result, LLM systems are generally robust in handling this variability.
Tasks with significant consequences require a calibrated LLM. A notional example is Air Force Master Air Attack Planning (MAAP). In the face of conflicting intelligence reports, the LLM must signal low confidence when asked to provide a functional damage assessment about an element of the adversary’s air defense system. Given the low confidence, human planners can select safer courses of action and issue collection requests to reduce uncertainty.
Calibration can offset LLM performance limitations, but only if a human can intervene. This is not always the case. An example is an unmanned aerial vehicle (UAV) operating in a communication denied environment. If an LLM for planning UAV actions experiences low certainty but cannot communicate with a human operator, the LLM must act autonomously. Consequently, tasks with low human oversight require a robust LLM. However, this requirement is influenced by the task’s potential consequences. No LLM system has yet demonstrated sufficiently robust performance to accomplish a safety critical task without human oversight.
Design Strategies to Enhance Safety
When creating an LLM system, a primary goal is to use models that are inherently accurate, calibrated, and robust. However, as shown in Figure 1 above, supplementary strategies can augment the safety of LLMs that lack sufficient robustness or calibration. Steps may be needed to enhance robustness.
- Input monitoring uses automated methods to monitor inputs. This includes identifying inputs that refer to topics not included in model training, or that are provided in unexpected forms. One way to do so is by measuring semantic similarity between the input and training samples.
- Input transformation develops methods to preprocess inputs to reduce their susceptibility to perturbations, ensuring that the model receives inputs that closely align with its training environment.
- Model training uses techniques, such as data augmentation and adversarial data integration, to create LLMs that are robust against natural variations and adversarial attacks. to create LLMs that are robust against natural variations and adversarial attacks.
- User training and education teaches users about the limitations of the system’s performance and about how to provide acceptable inputs in suitable forms.
While these strategies can improve the LLM’s robustness, they may not address concerns. Additional steps may be needed to enhance calibration.
- Output monitoring includes a human-in-the-loop to provide LLM oversight, especially for critical decisions or when model confidence is low. However, it is important to acknowledge that this strategy might slow the system’s responses and is contingent on the human’s ability to distinguish between correct and incorrect outputs.
- Augmented confidence estimation applies algorithmic techniques, such as external calibrators or LLM verbalized confidence, to automatically assess uncertainty in the system’s output. The first method involves training a separate neural network to predict the probability that the LLM’s output is correct, based on the input, the output itself, and the activation of hidden units in the model’s intermediate layers. The second method involves directly asking the LLM to assess its own confidence in the response.
- Human-centered design prioritizes how to effectively communicate model confidence to humans. The psychology and decision science literature has documented systematic errors in how people process risk, along with user-centered
Ensuring the Safe Applications of LLMs in Business Processes
LLMs have the potential to transform existing business processes in the public, private, and government sectors. As organizations seek to use LLMs, it must take steps to ensure that they do so safely. Key in this regard is conducting LLM capability assessments. To be useful, an LLM must meet minimum accuracy standards. To be safe, it must also meet minimum calibration and robustness standards. If these standards are not met, the LLM may be deployed in a more restricted scope, or the system may be augmented with additional constraints to mitigate risk. However, organizations can only make informed choices about the use and design of LLM systems by embracing a comprehensive definition of LLM capabilities that includes accuracy, calibration, and robustness.
As your organization seeks to leverage LLMs, the SEI is available to help perform safety analyses and identify design decisions and testing strategies to enhance the safety of your AI systems. If you are interested in working with us, please send an email to info@sei.cmu.edu.
Additional Resources
SEI chief technology officer Tom Longstaff describes the SEI’s approach to the predicted generative AI revolution.
Written By



More By The Authors
More In Artificial Intelligence Engineering
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed