A Game to Assess Human Decision Making with AI Support

When using decision-support systems that are based on artificial intelligence (AI), humans often make poor choices. The failure of these systems to reward expectations about their utility have led to several such systems being abandoned. Although preliminary research indicates that the inability to communicate model output understandably to the humans who use the systems may contribute to this problem, it is currently unknown what specific changes in the way that AI systems communicate with users would be most likely to increase their success. In this blog post, I describe SEI research that is collecting data on actual human decision making to determine the most effective designs for AI-system interfaces within a chosen domain.
Widespread adoption and application of AI is still in its infancy. Therefore, the ways in which a system's operation can be degraded or destroyed by human-AI interactions are not well understood. Recent failures of systems using AI illustrate this point. Here are two examples.
Identifying Lead-Based Hazards in Flint, Michigan
AI was used in the response to the 2019 water-supply crisis in Flint, Michigan. An AI system used public-records data, such as the year in which houses were constructed, to predict the locations of hazardous lead-based service lines to flag them for replacement. The system achieved better than 80 percent accuracy--lead was found in more than 80 percent of the potentially problematic service lines that the system identified, and the lines were replaced.
However, the system did not provide the capability for a homeowner or home dweller to look up a specific location and discover the status of service lines in that location. So, for example, a family might see the house next door being repaired and wonder why repairs had not been scheduled for their house. In this case, the system may have known that the service lines in their house had been replaced recently, and therefore did not contain lead. But the confusion and public outcry from poor communication with the people living in these potentially dangerous homes resulted in abandonment of the AI system.
The city of Flint ultimately replaced the AI system with one that tested all homes, neighborhood by neighborhood. In contrast to the 80 percent success rate of the AI system, the new system found hazardous lines in fewer than 15 percent of the homes tested, representing a huge waste of resources. However, the new system was more palatable to the Flint population, so it became the chosen solution. The AI system had failed because it did not take the human element into account.
The Thief Who Looked Like Woody Harrelson
During the course of a shoplifting investigation, an officer had access only to a low-quality picture of the suspect obtained from security footage. When the picture was entered into the department's facial-recognition system, the system was unable to produce matches with known criminals. But when the officer observed that the person in the grainy photo resembled the actor Woody Harrelson, he resourcefully downloaded a high-quality photo of Harrelson, ran that photo through the facial-recognition system, and this time the system matched the photo with some potential suspects, including one who was ultimately arrested and prosecuted for the crime.
In both instances--the grainy photo and the higher quality photo of Harrelson--the system performed as it was programmed to perform. But without the intervention of the officer, who was able to introduce a human element into a solution of the problem--in this case, the resemblance of the suspect with Woody Harrelson--the system would not have succeeded in identifying any suspects.
Researching the Human Use of AI Systems
These examples illustrate gaps in our knowledge of how best to design AI systems. Specifically, we need to know answers to questions such as these:
- How do we design decision-support systems that take humans into account when using AI?
- What are features of the interface that will lead to good decision making?
- What are the limits and pitfalls of current practice?
Every designer of an AI system today operates without any widely accepted or agreed-upon practices--or even an accepted methodology--for collecting information about how best to support good decision making on the part of the human. Systems acquirers also do not have a ready set of requirements that will guarantee optimal decision making in the decision-support systems that they acquire.
To best understand how AI-enabled systems are used--and misused--we must be able to collect data about system use under a variety of circumstances. However, as AI-enabled decision-support systems are coming into increasing use within the U.S. Department of Defense (DoD), current research literature is insufficient to guide designers. Two distinct bodies of research literature bear on this problem: (1) psychological research on human decision making and how humans interpret and react to uncertainty, and (2) nascent research on explainable AI (XAI).
The literature on explainable AI, including the majority of DARPA XAI projects, focuses on extracting information from an AI model. However, recent research has indicated that this information is incomprehensible for many individuals when used as the basis of decision making. Extensive literature from the fields of psychology and decision science documents how humans process information and make decisions in the face of uncertainty. To date, however, there has been little work integrating these disparate research threads.
To observe human decision making, we at the SEI created the Human-AI Decision Evaluation System (HADES). HADES allows the investigation and evaluation of AI-assisted human decision making in a variety of simulation environments, including environments not yet implemented. In addition, HADES allows the testing of multiple experimental designs to help determine which are most successful.
Our test environment focuses on cybersecurity decision making, which is a domain of critical interest to the DoD. By aligning the test environment with systems used in operational settings, we can ensure operational validity. Our criterion for success is an improvement in the average test subject's decision-making quality by at least 50 percent from their baseline performance.
Testing Human Decision Making in Games
The optimal setting for collecting data about actual system use by humans requires a human to repeatedly make the same type of decision over and over again, each time with slightly different information available. This sort of data collection allows us to gauge the effects of the slight differences. Such a task presented directly to a test subject would quickly induce fatigue and loss of interest. However, such repeated decision making is a common characteristic of games. The specific information available to a player can be modified in a game from turn to turn, without changing the core mechanics of the game. For this reason, a game-based interface is an ideal environment for collecting data about human decisions.
We integrated the HADES test harness into game environments to observe the effect of AI decision-support systems on gameplaying outcomes. HADES allows us to study the effects of information presentation and narrative context on human-AI decision-support systems within the context of a game. It also allows us to abstract what are the important features that have the largest effect on decision making for any given scenario. To determine what is the best interface for a given problem, we give people testing the interface a problem that contains the decision we are asking them to make. The AI system then makes a recommendation and we see what the test subjects choose to do; do they choose the right answer? To learn which interface practices work best, we ask subjects to make decisions repeatedly, each time changing slightly the elements of the interface.
For example, the simplest interface for the AI system is simply to tell the user what to do. In the absence of data, however, we don't know if this simplest interface is always optimal. Some systems convey to the user a confidence measure--the interface tells the user that it is 99.9 percent sure that the user should choose option A, or that it is 52 percent sure, or some other number. Before designing and implementing the system, we need to know whether showing the user a confidence measure is an important determinant of the user's ability or willingness to decide, as well as how high the confidence measure must be for the user to take the action that the interface recommends.
It is also important to know whether introduction of the confidence measure is productive or counter-productive. For example, it may be that a user, even when shown a confidence measure of 99 percent, could react by saying, "Oh, so it's not sure?" and then take an action that is contrary to what the system recommends. Another option for interface design might be to share or not to share with the user the data that the system is using as rationale for making its recommendation.
By implementing the HADES system in the context of a game, we could test a wide variety of options for the ways that the system communicates with the user, such as explicitly telling the user what to do, including or not including confidence measures, and sharing or not sharing rationale for recommendations. We then collect data on the success of each option. Until we test all of these slight permutations of interface options, we don't know which are optimal.
Our set of candidate design elements falls broadly into two categories: explainability elements and contextual elements. Explainability elements relate to providing information on why the AI system made the recommendation that it did. In contrast, contextual elements affect the context within which the decision is made (risks and rewards). In game terms, these map to informational and narrative elements.
The game interface, which requires repeated decision making in the context of a game, is uniquely well suited for testing such slight permutations. As users play the game, the system tracks all of the users' actions, which enables us to answer key questions, such as
- What information do they look at?
- How long do they look at it?
- What is the AI recommending?
- What elements of the recommendation do the users look at?
- Do the users end up agreeing with the AI or taking their own actions?
- Did they ultimately make the right or the wrong decision?
We track all of this information as the gameplaying progresses.
TGI Launch Day
TGI Launch Day is a game we designed to integrate with HADES to test how both contextual and design factors affect users' reactions to an AI-recommender system. In the game, players take on the role of a security analyst at a software company and they are tasked with fielding user requests for approval to run different software on company computers. Players are assisted in this task by an AI system that analyzes the requested software and provides a recommendation for whether the software should be approved or not. To support the HADES system, the game supported a number of design variations that we explored in a study.

During the game, players engage in scripted dialogue sequences with in-game characters (Figure 1). One design variation manipulates the stakes of the story that take place during these dialogue sequences. In the low-stakes version of the story, the players and their colleagues have heard rumors of a launch party for their company's new product that they will get invited to if they perform well at their jobs. In the high-stakes version, a malicious hacker is targeting the company, and the players must remain extra vigilant or else the product launch may be compromised.
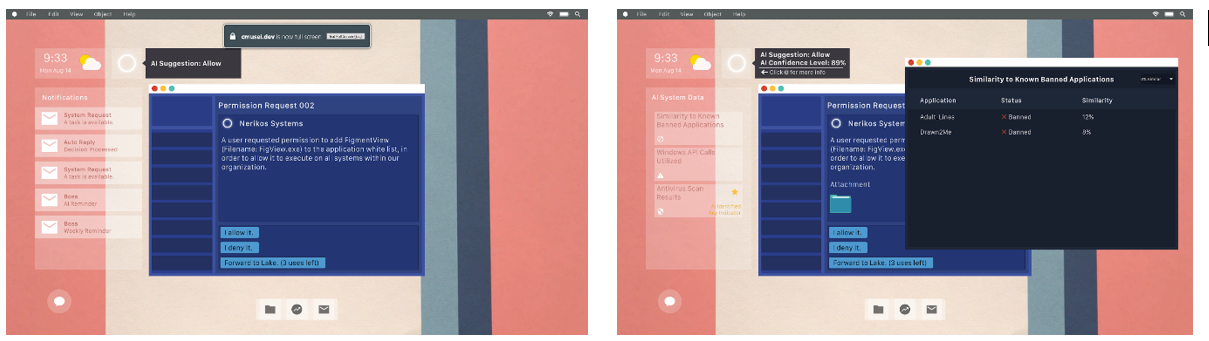
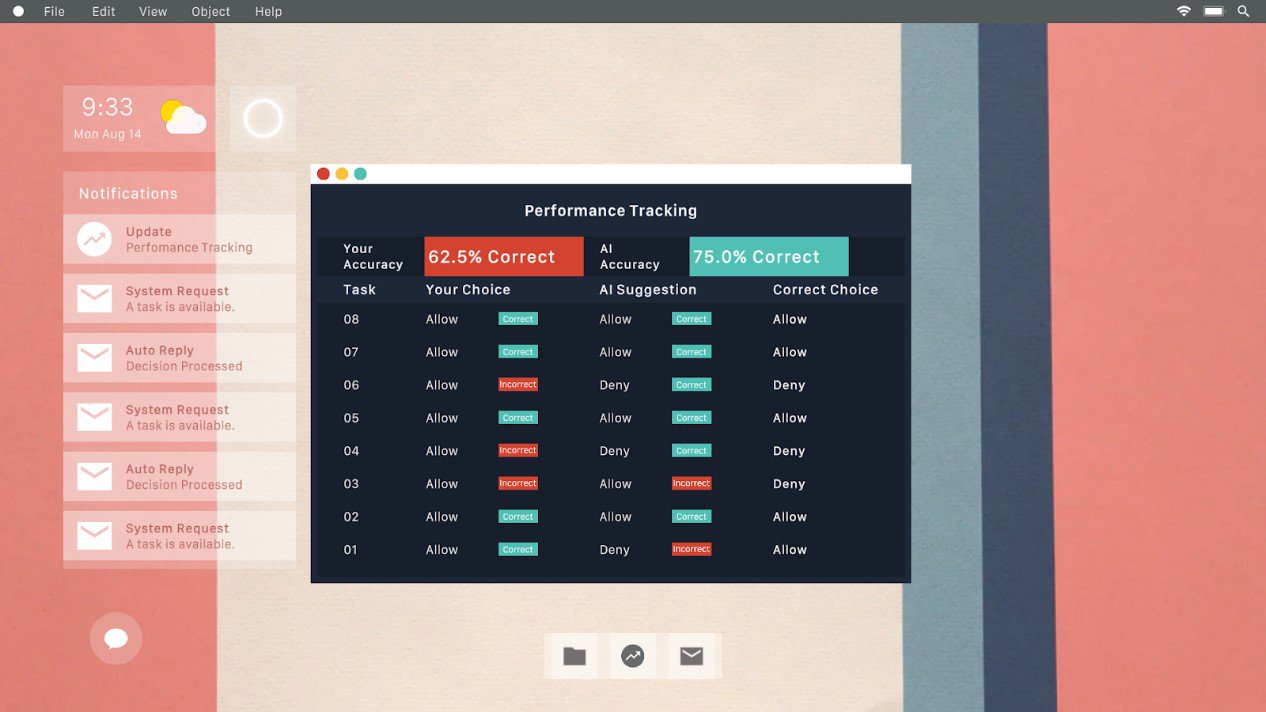
The decision tasks in the game are framed as emails sent to the players by coworkers requesting approval for various software to run on company computers. Players may choose to approve or deny requests, which are evaluated as correct or not. Alternatively, they have a limited number of opportunities to forward requests on to a security specialist who has limited capacity to deal with issues where the player is unsure, which is considered to be declining to make the decision. After the players have completed eight of these tasks, they start to receive performance reports (Figure 3) following each task that tracks their decision correctness against the performance of the AI system, so they can understand how well they are doing.
The decision-task interface is designed to support a number of condition variations that provide or withhold additional information about the AI's decision-making process to the user. In this initial study, we explored the far extremes of these features with a low-information condition (Figure 2 left), which provides no additional information to support the AI's recommendation, and a full-information condition (Figure 2 right), which provides a number of different resources for users to consult in making their decisions. Most saliently, the full-information condition provides an estimate of the AI's confidence along with its recommendation. This number is sampled within HADES based on the simulated AI's pre-defined accuracy of 85 percent. In addition to the confidence estimate, the full-information condition also provides diagnostic resources describing additional factors (such as the similarity of the request to known banned applications) that the AI would have considered in making its recommendation.
Preliminary Results Based on TGI Launch Day
Our study of TGI Launch Day provides encouraging evidence for the potential of HADES as a model for investigating users' reactions to different AI scenarios. By varying the narrative stakes, information availability, and compensation across players, we can make some conclusions about how users might react to AI-recommender systems in different settings.
We are in the process of publishing full results from this study. Some results relevant to matters I have discussed in this post include these:
- Participants improve over time--Our data show that the more participants play TGI Launch Day, the better they get at identifying malicious software requests.
- They also tend to trust the AI system more over time--as evidenced by a positive trend in agreement with the AI. Given that the AI system was defined within HADES to have an 85 percent accuracy rate at the task, it makes sense that participants would tend toward following its recommendations as they also improve in accuracy over time.
- For AI trust, there was a significant reversal effect of providing information to participants that counteracts the general trend of increasing trust over time--This result implies that participants who had additional insight into the AI's decision-making process remained roughly as skeptical of the system as they had been initially, while participants who were not given information tended toward trusting the system. There may be an incorrect assumption on the part of users that any recommendation given by an AI system is made with a high degree of confidence. This perceived confidence may be negated when doubt is expressed in the form of exposing the actual confidence measures, even if the stated confidence measure is higher than the performance they've come to expect from the system.
Future Applications of the HADES Test Harness
The HADES test harness can be applied to anything, not just a game. It can be applied to any AI-enabled system, even one that has not yet been designed. HADES can test a mockup and collect data on a proposed AI system without implementing the system, resulting in significant cost savings.
The flexibility of the HADES test harness should allow for a wide variety of systems to integrate with it, with minimal effort. A simple web query is all that is needed to interface with the HADES back end. This flexibility will allow other researchers to easily adapt HADES for their own research purposes. We are already exploring possible integrations with a variety of contexts (chess, math education, healthcare recommendations). We welcome queries from any researchers interested in using the HADES system. For more information, please contact us.
Additional Resources
Read other SEI blog posts about machine learning and artificial intelligence.
Written By

More By The Author
More In Artificial Intelligence Engineering
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed