Verifying Timing in Undocumented Multicore Processors

Many Department of Defense (DoD) systems rely on multicore processors--computers with many processor cores running programs simultaneously. These processors share resources and perform complex operations that depend on accurate timing and sequencing. Timing is crucial to ensure proper and safe operation of the overall system. Verifying multicore-processor timing can be hard, however, due to lack of documentation for key details, such as processor resource sharing. The inability to verify timing is an obstacle for using multicore processors in the types of mission- and safety-critical systems on which the DoD relies.
In this blog post, I describe an SEI project that has developed methods to verify the timing of software executing on multiple cores without requiring information about shared hardware resources. These methods could enable DoD programs to field hardware upgrades more rapidly and simplify testing required when new components replace old ones in a system.
Multicore Processors
Multicore processors are used to achieve greater computing power with lower power consumption and smaller size. Almost all computers today use multicore processors: they are the norm in desktop computing, servers, and mobile computing.
In multicore systems, one program can execute on one processor core and another program can execute on another processor core simultaneously. Typically, processor cores share memory. In today's memory system, a large number of resources (such as cache memory and memory bus) are used to make memory accesses faster in general. Unfortunately, however, this architecture also makes execution time more unpredictable and dependent on execution of other programs (because these other programs use shared resources in the memory system). A simplified view of a multicore processor with the memory system is shown in Figure 1. This figure shows three processor cores where each processor core has a level 1 and level 2 cache memory (these store frequently accessed data so that they can be accessed faster). There is also a level 3 cache memory that is shared between processor cores. The processor cores communicate with dynamic random-access memory (DRAM) banks (by reading from and writing to them) via a memory bus. The interested reader can find more detailed information about these resources and models of them in one of our earlier papers.

Real-Time Requirements in Multicore Systems
Many software developers are increasingly interested in using multicore processors in critical applications--for example, in automotive, medical devices, avionics, space, and defense. The DoD often employs them in embedded real-time cyber-physical systems as part of larger systems. For example, multicore processors are used in the upgrade of the UH-60V helicopter (Figure 2).

Photo: CPT Peter Smedberg
Multicore processors are also considered for Future Vertical Lift, one of the largest DoD programs.
Such applications pose additional hard real-time requirements on the software's design and operation. Satisfying hard real-time requirements is typically necessary when the software interacts with its physical world. For example,
- An airbag in a car must be inflated at the right time.
- A braking system in a car must apply the right braking force at the right time.
- Counter-measures in an aircraft must be deployed at the right time.
- Pacemakers must deliver stimuli at the right time.
Verifying timing guarantees is so hard that practitioners often disable all but one processor core, making multicore processors behave like single-core processors and sacrificing their benefits for easier verifiability. Such practices are not optimal, however. The importance of timing was recently stressed by AMRDEC's S3I Acting Director Jeff Langhout: "The trick there, when you're processing flight critical information, it has to be a deterministic environment, meaning we know exactly where a piece of data is going to be exactly when we need to--no room for error. On a multicore processor there's a lot of sharing going on across the cores, so right now we're not able to do that."
Undocumented Shared Hardware Resources
In such applications where hard real-time requirements must be satisfied, one of the main challenges software developers face is that the timing of software depends on how low-level hardware resources, such as those in the memory system, are allocated when requested to support the software's execution.
The one resource that is easiest to understand is the memory bus. If two processes, one on each processor, experience memory-cache misses simultaneously, both processes will request access to memory simultaneously, resulting in two requests to use the same memory bus. Unfortunately, both cannot be served simultaneously; hence one of these requests will be queued and will experience an increase in execution time. For memory-intensive applications, our team and those with whom we have collaborated have experienced anywhere from a 300 percent to 1,100 percent increase in execution time due to sharing of resources in the memory system. Clearly, if such resource contention is not accounted for in the analysis at design time, timing requirements may be violated at runtime, resulting in mission failure or disaster in which interaction with the physical world does not occur at the right time. The sharing of another resource (called miss-status holding register) can cause an even greater effect on timing--the execution time of a program can increase 103-fold.
The challenge of analyzing the timing of resource contention in the memory system of multicore processors is an issue both in greenfield development of software for multicores and in transitioning legacy code to multicore processors. Figure 3 depicts one such challenge.
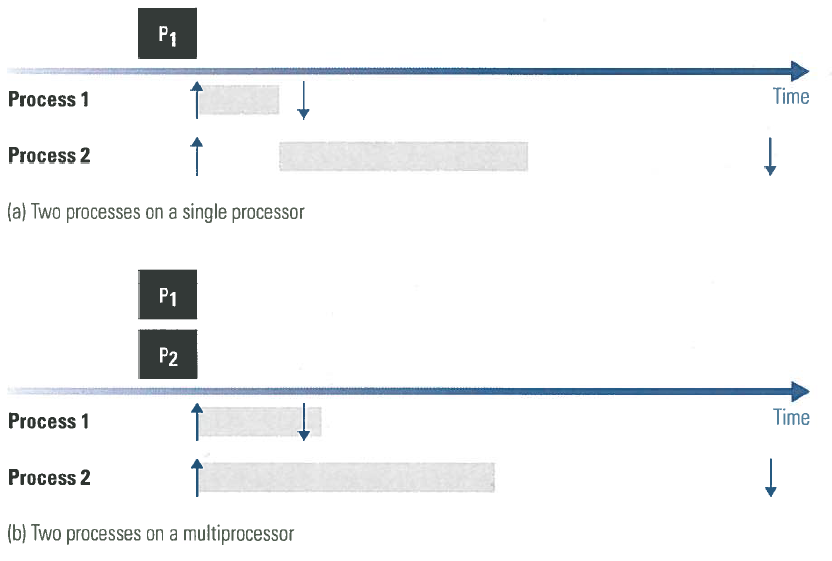
Figure 3a shows a legacy software system using a single hardware processor with two software processes where the timing requirements are satisfied. An arrow pointing up indicates the time when a process is requested to execute and an arrow pointing down indicates the deadline of a process. Figure 3b shows that when the same software is migrated to a multicore processor with two hardware processors on a chip, a timing requirement is violated. Hence, care must be taken when migrating legacy real-time software to a multicore since we expect all major software systems to undergo this transition to multicore processors as the commercial marketplace evolves.
Analyzing the timing of contention for resources in the memory system of multicore processors is hard for several reasons. First, the number of schedules (or interleavings) of the processes is large, so it is not possible to check all of them manually. Second, the timing analysis of memory contention depends on operation of the memory system, and it is often not possible to construct models to mimic that operation because hardware makers typically do not disclose the internals of the memory controller.
The number of possible schedules is too large to manually check each one. We need a verification technique that proves correct timing without enumerating all possible schedules. Such verification requires a model of both the software and the hardware; the latter requires documentation of which hardware resources exist and how they are shared.
Unfortunately, for many hardware resources that lack extensive documentation, developers must make assumptions about how shared hardware resources work. Even where documentation exists, technology evolves quickly, and a software system verified on today's hardware may not function the same on future hardware. In theory, the industry could put even more effort into modeling every resource and interaction as operations grow more complex, but it is hard to model everything in a dynamic environment characterized by perpetual change.
A Solution for Verifying the Timing of Software Executing on a Multicore
To address this challenge, we at the SEI developed a method for verifying the timing of software executing on multicores without information about shared hardware resources. In collaboration with Hyoseung Kim (University of California, Riverside) and John Lehoczky (Thomas Lord Professor of Statistics, Statistics Department, Carnegie Mellon University), we developed a model that describes the effect that the execution of one program can have on the execution of another program. This model then becomes input to a tool that can prove that the overall software system has correct timing.
The current state of the art makes solutions available for managing contention for resources in the memory system and for analyzing the impact of this contention on timing for the case in which we know the resources in the memory system. In our project, we have addressed the problem of verifying timing of software executing on a multicore processor assuming that we do not know the resources in the memory system.
In modeling the effect that one process has on another, our preliminary method does not model the actual hardware. Instead, it models how much longer the execution time of one process is when it executes in parallel with another process. With this model, it is possible to prove that all timing requirements are satisfied for all schedules that the system can generate.
To understand how our method works, consider a process that requests to execute periodically; we call each of these requests a "job." Assume that job J requires 5 units of execution and has a deadline of 9 time units. If J executes alone in the system, then J executes with speed 1; for this case, J meets its deadline. If, however, there is another job J' executing on another processor causing the execution speed of J to be 1/2, then J needs to execute for 10 time units to finish; for this case, J misses its deadline. We say that job J has corunner-dependent execution time.
For the purpose of timing verification, it is common to create a model where each process is associated with parameters (e.g., period, deadline, execution time); such a process is called "task." A schedulability test is a software tool that performs timing verification of a set of tasks. A schedulability analysis for tasks with corunner-dependent execution times would offer the following advantages to software practitioners:
- It would allow schedulability analysis to be used on commercial off-the-shelf (COTS) multicores where information about hardware resources and their arbitration is not publicly available.
- It would allow schedulability analysis to be used on future COTS multicores without having to invent a new task model or schedulability test.
- It would allow a software practitioner to use models that are suitable for each phase in a design process (e.g., coarse-grained description of corunner dependence early in the design process and detailed description later in the design process).
In the article Schedulability Analysis of Tasks with Co-Runner-Dependent Execution Times, my colleagues and I describe in detail a model and associated schedulability test for tasks with corunner-dependent execution times. We have implemented our schedulability test as a tool and evaluated it in two ways. First, we generated systems with up to 16 tasks and eight processors randomly and applied our schedulability test as well as a baseline schedulability test based on previous work. We found that
- Our schedulability test can guarantee significantly more systems than the baseline.
- For most systems, our schedulability test finishes within a few seconds.
- For some of the largest systems, it can take eight minutes for the schedulability test to finish, but for no system did the schedulability test take longer than that.
We also ran experiments with fewer processors and found that the schedulability test finished within 1,000 seconds for all systems with two processors and 128 tasks, and also for all systems with four processors and 32 tasks. Second, we used a real multicore platform and generated a software system for it. We characterized its parameters with our model, applied our schedulability test on this model, and ran the software on this computer to measure response times. We found no case where measurements violated the guarantee provided by our schedulability test.
Wrapping Up and Looking Ahead
By using a method such as ours, the DoD could field hardware upgrades more rapidly. Our method decreases the amount of testing required when new components replace old ones in a system. Instead of creating a new model built on new assumptions to verify the system again, the upgrade effort would feed new numbers into the same descriptive model for faster results.
We are currently working on developing
- methods for extracting taskset parameters from actual software systems,
- configuration procedures that reduce intercore interference, and
- schedulability analysis that is exact or close to exact.
Future blog posts will provide updates on our progress in these areas.
Additional Resources
Read the article, Schedulability Analysis of Tasks with Co-Runner-Dependent Execution Times.
Read other SEI blog posts about cyber-physical systems.
Read other SEI blog posts about multicore processing and virtualization.
Written By

More By The Author
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed