The SPRUCE Series: 9 Recommended Practices for Managing Operational Resilience

Software and acquisition professionals often have questions about recommended practices related to modern software development methods, techniques, and tools, such as how to apply agile methods in government acquisition frameworks, systematic verification and validation of safety-critical systems, and operational risk management. In the Department of Defense (DoD), these techniques are just a few of the options available to face the myriad challenges in producing large, secure software-reliant systems on schedule and within budget.
In an effort to offer our assessment of recommended techniques in these areas, SEI built upon an existing collaborative online environment known as SPRUCE (Systems and Software Producibility Collaboration Environment), hosted on the Cyber Security & Information Systems Information Analysis Center (CSIAC) website. From June 2013 to June 2014, the SEI assembled guidance on a variety of topics based on relevance, maturity of the practices described, and the timeliness with respect to current events. For example, shortly after the Target security breach of late 2013, we selected Managing Operational Resilience as a topic.
Ultimately, SEI curated recommended practices on five software topics: Agile at Scale, Safety-Critical Systems, Monitoring Software-Intensive System Acquisition Programs, Managing Intellectual Property in the Acquisition of Software-Intensive Systems, and Managing Operational Resilience. In addition to a recently published paper on SEI efforts and individual posts on the SPRUCE site, these recommended practices will be published in a series of posts on the SEI blog.
The first post in this series by Julia H. Allen, Pamela Curtis, and Nader Mehravari, presented challenges for managing operational resilience. This post presents recommended practices for helping organizations manage operational resilience as well as strategies for making the best use of the recommended practices.
Recommended Practices for Managing Operational Resilience in Organizations
https://www.csiac.org/reference-doc/managing-operational-resilience/
1. Governance and program management. Organizations must oversee and manage the execution of resilience activities. Resilient organizations ensure that all such activities derive their purpose and focus from strategic objectives and critical success factors for operational resilience. The governance and program-management practice ensures that the investment in operational resilience, cybersecurity, service continuity, and other domains is consistent with the organization's business objectives. This practice entails regular planning, definition of roles and responsibilities, adequate funding, appropriate resource allocations, oversight in executing the plan, and corrections as necessary. In addition, governance and program management involves measuring, analyzing, and reporting the effectiveness of resilience-management practices and implementing improvements. These are all standard business practices for successful, mature organizations, but they are often overlooked when managing operational resilience.
2. Staff preparation and deployment. Organizations must be prepared when a disruptive event occurs. That means making sure that staff at all levels of the organization are trained in how to perform their assigned roles when disruptions occur. Everyone must know his or her role, receive training, and rehearse plans and contingencies. Skill gaps and deficiencies should be identified and training provided to address them.
Training can be designed to help meet the goals of resilience management as well as other goals of the organization that depend on interdisciplinary team performance. For example, teams with members drawn from different disciplines and departments can train together in a scenario that encourages interaction, mutual understanding, and building trust among team members. Such training breaks down barriers that otherwise naturally arise when work must be done across disciplines and departments.
This practice also encompasses establishing staff backup and redundancy at all levels of the organization. For key personnel, not only it is important to have backups who can step in; organizations should also have identified qualified successors to staff members in key positions if those positions are vacated.
Training is not a one-time event. The organization should provide periodic refreshment training for all key functions so that responsibilities and skills are not forgotten in the stress of disruptive events.
3. Communication and awareness. Resilient organizations make establishing and maintaining communications with stakeholders a key objective in all operational resilience-management practices--both during normal operations and during periods of stress. Communication is always important, but it is particularly essential during times of disruption. The organization should plan in advance exactly who will contact whom during and following disruptive events. Plan who will communicate with stakeholders, including both customers and suppliers, to share information and make stakeholders aware of the status of the situation. In addition, develop communication methods (newsletters, email notifications, community meetings, etc.), channels (public relations activities, peer and professional organizations, etc.), infrastructure, and systems (such as emergency alerting via mobile devices).
This practice includes both internal and external communication. An organization should report ongoing measurement of operational performance and resilience-management activities and disseminate that information across the enterprise to ensure that all organizational units are operating with an up-to-date picture of the organization's operations. External communication tasks may require providing information to news media about its resilience efforts or efforts to contain an incident or event. As appropriate, establish responsibility for planning or and executing crisis communications among first responders, other emergency and public service staff, and law enforcement.
4. Risk management. Organizations must identify, analyze, and mitigate risks to assets that could adversely affect the operation and delivery of high-value services. Because an organization cannot protect against every possible threat, risk management involves identifying critical services and operations, identifying the assets that enable their delivery, and prioritizing them. Based on the strategic objectives established in Practice 1, an organization identifies, analyzes, and prioritizes the set of risks that it will monitor and mitigate. This means that some risks will not be addressed, whether intentionally or accidentally. The goal of risk management is to limit exposure to the latter, but an organization can simply accept some risks and monitor them as residual risks (e.g., a price increase for a critical purchased component). In this way, the organization knows that it has an exposure but has attempted to intelligently limit that exposure.
Risk management is a continuous process involving identifying new risks, updating the status and disposition of identified risks, determining how to handle the risks (e.g., prevent, mitigate, monitor, or accept), and implementing the selected risk-handling option. For most organizations, this includes cyber risks--and, more specifically, software vulnerabilities and malware. A large body of work by the Software Engineering Institute and the MITRE Corporation describes specific vulnerabilities and software weaknesses. In particular, MITRE has established a large resource in its Common Vulnerability and Enumeration (CVE) repository, where it makes classes of vulnerabilities and solutions available.
5. Incident management. Incident management is one of the disciplines that most naturally comes to mind when one considers operational resilience management. It is the end-to-end handling of a disruptive event from the time that something happens to when it is detected, triaged, and resolved. Disruptive events include deliberate or inadvertent harmful actions of people, failed internal processes, technology failures, and external events such as natural disasters and power outages. Implementing this practice begins before an incident occurs, when an organization plans for and assigns roles and responsibilities, including those for key stakeholders and decision makers (for escalation).
Operational staff should be trained not only in delivering the services and conducting the operations for which they have responsibility but also in the results and effects to expect from performing these services and operations. Operational staff are often the first staff capable of detecting an incident; thus such training should make them more sensitive to unexpected deviations from "normal" results and effects. Once an incident is detected, the first step is to carefully note the circumstances of the incident, declare the incident, and preserve evidence. The organization may have prepared an immediate workaround for just such an incident. If so, that workaround is often implemented by the same staff who detect the incident. Otherwise, the organization analyzes the incident to develop an appropriate response, including recovery actions that minimize the disruption. When analyzing the incident, the incident-handling team looks for patterns or similarities to other incidents that they may have seen in the past. The organization may perform a root-cause analysis and identify and evaluate multiple candidate solutions.
The next steps are to implement the solution--respond and recover. The incident-handling team should also ensure that the organization communicates with key stakeholders, who can provide needed resources and expertise immediately or later in the incident resolution.
Once the incident is closed, the organization should conduct a postmortem analysis to determine if the organization should make any improvements to its overall incident management, risk management, and service delivery (operations) processes. The organization should define measures to help evaluate the effectiveness of its responses to disruptive incidents. It will analyze those measures of effectiveness to determine where to improve its practices.
6. Service continuity. This practice entails ensuring the continuity of essential operations and services during and following a disruptive event. Service continuity may include business continuity, disaster recovery, crisis management, and pandemic planning.
Activities encompassed by this practice include developing service-continuity plans, assigning roles and responsibilities, and then testing plans and running exercises to ensure that the plans are robust. For example, the organization should establish plans about what to do with its workforce if it must evacuate its facility and stand up an alternative facility to continue operations. Tests and exercises can cover a wide range of activities and may include computer simulations.
Organizations should ensure the continuity of the services they provide through careful preparation and planning. The resilient organization tracks the location of key personnel and backup personnel, so that in the event of an incident, they can put recovery plans into action. Through exercises and drills, the organization assures that everyone knows his or her roles. When a Hurricane Sandy happens, the resilient organization does what it has rehearsed.
7. Critical asset protection. Critical assets (e.g., information, technology, facilities) that support high-value services must be identified, protected, and maintained. In particular, an organization must ensure that it applies adequate controls to protect the confidentiality, integrity (i.e., information security), and availability of information essential or entrusted to the business. Such controls can include maintaining an up-to-date inventory of the information that the organization must protect, on what devices that information resides, and over what networks it may be transmitted. In addition, an organization should have practices for configuring, tracking, protecting, and maintaining its IT assets (e.g., workstations, laptops, mobile devices, and network components).
Protecting critical assets requires continually identifying and mitigating threats to the asset (e.g., as part of a comprehensive risk-management practice, discussed in Practice 4); improving, retiring, and adding new controls to the asset to maintain its integrity; and establishing appropriate identity and access management to limit access to the asset. Critical asset protection also includes facility protection, such as for an organization's IT assets, and includes facilities for backup and recovery.
8. External-dependencies management. An organization must identify and manage dependencies on external entities, such as its supply chain. Key elements of this practice include prioritizing external dependencies, managing risks arising from external dependencies, and formalizing relationships with external entities. Organizations should make sure that formal and contractual agreements are in place with external entities and that everyone understands what is expected from each party, in particular with respect to disruptions in delivery of critical components or services. To ensure preparedness, an organization should proactively monitor and manage the performance of external entities to make sure they meet expectations.
9. Secure software development and integration. Organizations must ensure that software that enables or performs the delivery of critical services and operations satisfies resilience requirements. An organization derives resilience requirements for such software in part from its resilience-management activities, including governance and program management (Practice 1), service continuity (Practice 6), and critical asset protection (Practice 7). For example, mitigating a particular threat to an asset may impose resilience (and security) requirements on the software that controls it or access to it. An organization should also elicit or collect requirements from stakeholders, including customers, end users, suppliers, other partners, and regulatory authorities. Multiple frameworks provide recommended practices for software development that address security and other resilience-related topics (see Learn More for more information). Many of the challenges noted for practices at the top of this webpage apply to the practices described in such frameworks as well.
How to derive more benefit from the recommended practices for managing operational resilience?
1. Coordinate the implementation of these practices. Implementing these practices requires competence in several disciplines (incident management, asset protection, risk management, etc.). Organizations that create a separate solution or team to deal with each practice will find their operational resilience-management activities to be inefficient and difficult to manage due to the overlaps (e.g., where do incident management, disaster recovery, and asset protection and sustainment begin or end?). Just as the implementation of each operational resilience-management practice should be driven by business objectives, so should their collective implementation. Organizations will improve their operational resilience by taking an integrated approach to implementing these activities and ensuring that there is adequate coordination among them.
Begin by gathering representatives from the different disciplines and departments to develop end-to-end scenarios that describe how the organization should respond to particular threats (as described in Practice 2). Identify which disciplines or departments (e.g., incident analysis, disaster recovery, and crisis communication) to involve at each stage of the response, including afterward, when making improvements to processes and training for service delivery, service continuity, and information security. Then determine how the organization should coordinate its activities in such scenarios. Such rehearsals or simulations help identify superior ways to implement the operational resilience-management practices.
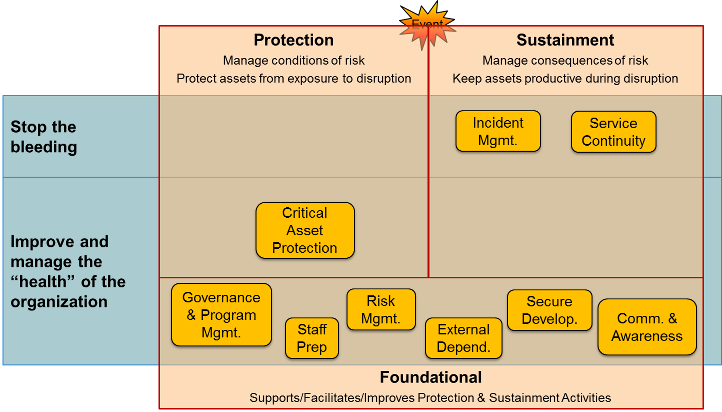
The following diagram may help you remember the purpose of each resilience-management practice. The two practices in the "Stop the bleeding" row deal primarily with resolving incidents. The "Improve and manage" row of the diagram depicts the practices that provide infrastructural and foundational support for establishing, facilitating, measuring, and improving asset protection and operations sustainment activities. The position of those practices in the diagram also indicates their role in protecting and sustaining the health of the organization and continually improving operational resilience-management activities. The diagram illustrates the need for all the operational resilience-management practices to work together.
2. Maintain currency with relevant standards. In the past 10 years, standards have exploded across all disciplines in national and international efforts to deal with the growing number of cybersecurity failures. The number of standards dealing with preparedness planning has quadrupled since 2005. An organization should develop an integrated approach to updating its processes to maintain compliance with standards relevant to its business. For example, when ISO/IEC Standard 27034 Information Technology--Security Techniques--Application Security was published, its guidance affected business managers, IT managers, developers, auditors, and end users. An organization should involve designers, programmers, acquisition managers, IT staff, and users to determine what changes are needed to preserve the effectiveness of operational resilience-management activities while addressing this standard.
3. Understand compliance issues. Compliance issues affect all the recommended practices. An organization must not only follow federal and state legislation and regulations but also be aware that state-by-state differences exist. For example, state requirements vary for notifications about data breaches, and this will inform the organization's communication practices. However, an organization should view compliance as an outcome of an integrated operational resilience-management program, not a goal. Simply following a rule may not be sufficient to plan for and mitigate risk; new risks arise much faster than the rate of legislation.
Looking Ahead
Technology transition is a key part of the SEI's mission and a guiding principle in our role as a federally funded research and development center. The next post will in this series will present recommended practices for the software development of safety-critical systems.
We welcome your comments and suggestions on this series in the comments section below.
Additional Resources
For comprehensive information about CERT's research operational resilience management, please see www.cert.org/resilience.
For more information about frameworks and maturity models, please see Buyer Beware: How to be a Better Consumer of Security Maturity Models presented by Julia Allen and Nader Mehravari at the February 2014 RSA Conference.
Richard A. Caralli, Julia H. Allen, and David W. White, also published the book CERT Resilience Management Model (CERT-RMM): A Maturity Model for Managing Operational Resilience by Addison-Wesley Professional, 2011.
A detailed list of resources for managing operational resilience, frameworks and maturity models, risk management, external dependencies management, resilience engineering, operational resilience management, and resilience policy development, please visit
https://www.csiac.org/reference-doc/managing-operational-resilience/.
Written By

More By The Author
7 Recommended Practices for Managing Intellectual Property in the Acquisition of Software-Intensive Systems
• By SPRUCE Project
7 Recommended Practices for Managing Intellectual Property in the Acquisition of Software-Intensive Systems
• By SPRUCE Project
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed