Developing a Software Library for Graph Analytics


Graph algorithms are in wide use in Department of Defense (DoD) software applications, including intelligence analysis, autonomous systems, cyber intelligence and security, and logistics optimizations. In late 2013, several luminaries from the graph analytics community released a position paper calling for an open effort, now referred to as GraphBLAS, to define a standard for graph algorithms in terms of linear algebraic operations. BLAS stands for Basic Linear Algebra Subprograms and is a common library specification used in scientific computation. The authors of the position paper propose extending the National Institute of Standards and Technology's Sparse Basic Linear Algebra Subprograms (spBLAS) library to perform graph computations. The position paper served as the latest catalyst for the ongoing research by the SEI's Emerging Technology Center in the field of graph algorithms and heterogeneous high-performance computing (HHPC). This blog post, the second in our series, describes our efforts to create a software library of graph algorithms for heterogeneous architectures that will be released via open source.
The Opposite of an Embarrassingly Parallel Problem
In computer science, the term embarrassingly parallel problem describes a situation where the same operation or set of operations can be executed on different data simultaneously, thereby allowing the distribution of data across many computing elements without the need for communication (and/or synchronization) between the elements. The problems are relatively easy to implement on high-performance systems and can achieve excellent computing performance. High-performance computing (HPC) is now central to the federal government and many industry projects, as evidenced by the shift from single-core and multi-core (homogenous) central processing units (CPUs) to many-core and heterogeneous systems, including graphics processing units (GPUs) that are adept at solving embarrassingly parallel problems.
Unfortunately, many important problems are not embarrassingly parallel including graph algorithms. Fundamentally, graphs are data structures with neighboring nodes connected by edges. The computation to be performed on graphs often involves finding and ranking important nodes or edges, finding anomalous connection patterns, identifying tightly knit communities of nodes, etc. The irregular structure of the graphs makes the communication to computation ratio high for these algorithms--the opposite of the ratio found in embarrassingly parallel problems--and thus extremely hard to develop implementations that achieve good performance on HPC systems.
We are targeting GPUs for our research not only because of their prevalence in current HPC installations (e.g., for simulating three-dimensional physics), but also because of their potential for providing an energy-efficient approach to the computations. We are investigating different approaches, including the linear algebra approach offered by the GraphBLAS effort, to enable the efficient use of GPUs and pave the way for easier development of high-performance graph algorithms.
Implementation
As detailed in our technical note, Patterns and Practices of Future Architectures, the first milestone in our research was to implement the most basic graph algorithm on GPUs: the breadth-first search (BFS), which also serves as the first algorithm included in the Graph 500, an international benchmark specifically tailored to graph algorithms that measures the rate at which computer systems traverse a graph. The benchmark for this algorithm is divided into two kernels:
- graph construction (Kernel 1)
- breadth-first search traversal (Kernel 2)
The Graph 500 also provides the specification and a reference implementation for generating graphs with the desired scale-free properties (using a Kronecker generator); a parallel pseudorandom number generator (PRNG); guidelines for how the kernels are invoked, timed, and validated; and procedures for collecting and reporting performance results from Kernel 2, which is used to rank the systems on the Graph 500 list.
An early accomplishment of our work was to decouple those kernels from the benchmark's reference implementation. The resulting code is not part of either kernel and is invariant with respect to the specific BFS algorithms implemented and forms a software framework within which we develop and evaluate our BFS algorithms. The resulting framework, written in C++, allows us to directly compare different implementations, knowing that the graph properties and measurements were consistent (for a more detailed explanation of our implementation, please see our technical note).
Next, we concentrated our efforts on evaluating a number of different data structures for representing graphs. Due to the low computation-to-communication ratio, a graph's representation in memory can significantly impact the corresponding algorithm's performance. The following data structures and computer architectures were evaluated using systems from the ETC cluster containing up to 128 CPU cores, and dual NVIDIA GPUs:
- Single CPU, List. The baseline single CPU implementation is a single-threaded, sequential traversal based on Version 2.1.4 of the Graph500 reference implementation. This baseline is the simplest implementation of BFS and results in poor performance as a result of the unpredictable memory accesses.
- Single CPU, Compressed Sparse Row. Much research has already been performed and published to address the memory bottleneck in graph algorithms. One popular alternative to the list structure on CPU architectures is called the compressed sparse row (CSR), which uses memory more efficiently to represent the graph adjacencies by allowing more sequential accesses during the traversals. Using this data structure resulted in improved performance and allowed larger graphs to be manipulated.
- Single GPU (CSR). The baseline GPU implementation is an in-memory CSR-based approach described in papers by Harish and Narayanan. The wavefront-based approach in this algorithm is very similar to the behavior in single CPU implementations, except the parallelism requires the graph to synchronize between each ply of the traversal to ensure the breadth-first requirement is upheld.
- Multi-CPU, Combinatorial BLAS (CombBLAS). This approach is the precursor to the GraphBLAS effort mentioned in the introduction and is detailed in a research paper by Aydin Buluc and John R. Gilbert, which is an "extensive distributed-memory parallel graph library offering a small but powerful set of linear algebra primitives specifically targeting graph analytics." CombBLAS is a multi-CPU, parallel approach that we use to compare to the parallel GPU approach.
Our results for these implementations are shown in Figure 1 below. The complexity of programming these architectures is a primary concern, so the performance of the BFS traversal (Kernel 2) is plotted against the relative amounts of code required both to build the efficient data structures (Kernel 1) and implement the traversal (Kernel 2).
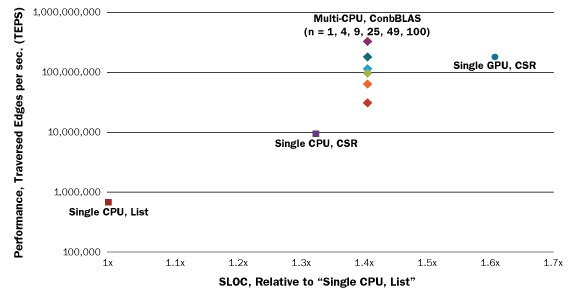
Figure 1. Performance BFS traversal (Kernel 2) relative to source lines of code (SLOC), a proxy for implementation complexity.
The results from the two single CPU implementations confirmed that the data structures used to represent the graph can significantly affect performance. Moreover, the CSR representation leads to an order of magnitude improvement in performance as measured in traversed edges per second (TEPS). Using the CSR data structure in the development of a single GPU traversal achieves another order of magnitude performance improvement.
The Challenge
Note that, as performance of these implementations increases, so does the amount of code required to achieve that performance (about 30 percent more for CSR, 60 percent more for CSR on GPU). Advanced data structures for graph analytics is an active area of research in its own right. Add to that the increasing complexity of emerging architectures like GPUs and the challenges are multiplied. To achieve high performance in graph algorithms on these architectures requires developers to be an expert in both. The focus of our work is therefore to find the separation of concerns between the algorithms and the underlying architectures, as shown by the dashed line in Figure 2 below.
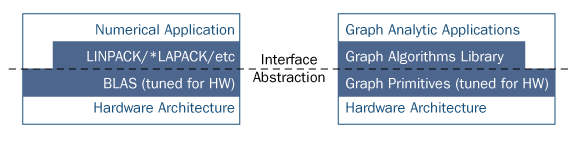
Figure 2. The architecture of the graph algorithms library that captures the separation of concerns between graph algorithms and the complexities of the underlying hardware architecture. It is similar to the architectures of computation-heavy scientific applications that depend on highly tuned implementations of the BLAS specification.
The graph algorithm library we are developing for GPUs is aimed at achieving this goal. If we are successful, our library will hide the underlying architecture complexities in a set of highly tuned graph primitives (data structures and basic operations), allow for easier development of graph analytics code, and maximize the power of GPUs. Part of the benefit of our approach is that the graph analytics community will be able to take advantage of it once it is complete.
Enter BLAS
There is a robust effort already underway in the academic research community focused on data structures and patterns. One approach to address this challenge has been suggested by the graph analytics community. Called GraphBLAS, this effort proposes to build on various existing technologies used commonly in the high-performance scientific computing community. GraphBLAS proposes to build upon the ideas behind sparse BLAS (spBLAS) to represent graphs and a parallel framework like Message Passing Interface (MPI) to scale out to multiple CPUs. A proof-of-concept implementation of this approach, called CombBLAS, was recently released by Aydin Buluc and John R. Gilbert. We also implemented this approach on our 128-CPU system and showed (in Figure 1) that we could scale to multiple CPUs and achieve more than 30X performance improvements over the "Single CPU, CSR" approach.
We also achieved a 2X performance improvement over our GPU implementation. Just as importantly, however, we achieved this improvement with 15 percent less code by leveraging existing libraries. There exist similar technologies for GPUs and our goal is to develop a library that hides the underlying complexity of these approaches, and implements a number of key graph algorithms. We presented our work to the community at a GraphBLAS birds of a father session at the 2014 IEEE High Performance Extreme Computing Conference (HPEC).
Collaborations and Future Work
Our research bridges the gap between the academic focus on fundamental graph algorithms and our focus on architecture and hardware issues. In this first phase of our work, we are collaborating with researchers at Indiana University's Center for Research in Extreme Scale Technologies (CREST), which developed the Parallel Boost Graph Library (PBGL). In particular we are working with Dr. Andrew Lumsdaine who serves on the Graph 500 Executive Committee and is considered a world leader in graph analytics. Researchers in this lab worked with us to implement and benchmark data structures, communication mechanisms and algorithms on GPU hardware.
Dr. Lumsdaine's team has experience in high-level languages for expressing computations on GPUs. The team created a new language, Harlan, for expressing computations of GPUs that is available via open-source. Researchers at CREST have used Harlan as a springboard to implement graph algorithms on GPUs and further explore programmability issues with these architectures. This work provided insight into graph algorithms, but also additional insights into Harlan and where it language can be extended.
We are also collaborating with Dr. Franz Franchetti, an associate professor in the Department of Electrical and Computer Engineering at Carnegie Mellon University. Dr. Franchetti is also involved in the GraphBLAS community, and is performing research in the programmability of graph algorithms on multi-CPU systems. Through our collaboration, we are hoping that multi-core CPU programming can translate to GPU programming (GPUs can be thought of as many small CPUs on a single core).
This year, we will also be collaborating with the CERT Division's Network Situational Awareness Group (NetSA). Working with their network data, we will compare the performance of our approaches on commodity GPU hardware with results they have achieve using a supercomputer specially designed to perform graph computations at the Pittsburgh Supercomputing Center.
Many supercomputers have multiple compute nodes (CPUs) with accelerators, like GPUs, connected. For many applications, the accelerators are vastly under-utilized, often due to the complexity of the code needed to run efficiently on them. Our long-term goal is therefore to release a library that will allow our customers and the broader HPC community to more easily and more efficiently utilize them in the growing field of graph analytics.
We welcome your feedback on our research in the comments section below.
Additional Resources
To read the SEI technical note, Patterns and Practices for Future Architectures, please visit https://resources.sei.cmu.edu/library/asset-view.cfm?assetid=300618.
Written By


Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed