New Study: How to Assess Large Language Model Fitness for Software Engineering and Acquisition

• Article
January 17, 2024—Large language models (LLMs) hold promise for efficiency and productivity gains, including in organizations with large software operations like the Department of Defense. But the number and variety of potential LLM use cases, as well as the technology’s still-emerging costs and drawbacks, make it hard to know when an LLM is the right solution. A recent Software Engineering Institute (SEI) white paper can help technical leads, program managers, and other decision makers to assess the fitness of LLMs for software engineering and acquisition.
Generative artificial intelligence (AI) applications such as ChatGPT, CoPilot, and Bard use LLMs trained on large data sets to quickly create plausible text, images, or code. Software-focused organizations are experimenting with these tools to gain efficiency across the acquisition and development lifecycle, but their use is not without risks. For example, LLMs might require an organization’s proprietary or sensitive data, and generative AI applications sometimes fabricate information. Amid these risks and the proliferation of LLMs, there is little guidance to help decision makers know when to use one.
To fill this gap, a team of SEI experts in government software engineering and acquisition programs analyzed LLM types, use cases, concerns, and mitigations. The resulting white paper, Assessing Opportunities for LLMs in Software Engineering and Acquisition, provides a structured way for decision makers to assess whether an LLM fits a particular use case.
The SEI researchers began by brainstorming dozens of use cases for LLMs across the breadth of software engineering and acquisition processes. Each use case defines the actor, the task, and the expectations for the results.
“Using LLMs throughout software engineering and acquisition touches on a lot of different stakeholders who have very different skill sets,” said James Ivers, an SEI principal engineer and co-author of the paper. Test engineers, for example, may be more critical of LLM output than program managers. “Knowing what LLM users expect helps set a yardstick of what's good enough.”
It is also important to consider the users when assessing LLM safety. The models are bound to make mistakes, and the users are responsible for catching them. “You've got to think about the human and the AI together, not just the LLM by itself,” said Ivers. Organizations should consider the magnitude of a mistake’s consequence versus how hard it is for a human to identify the mistake when taking advantage of LLMs, as illustrated by a quad chart in the paper.
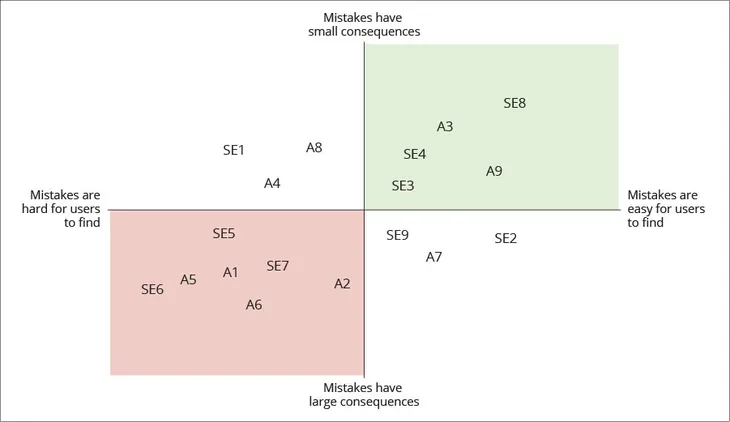
Two ways to look at concerns with the generation of incorrect results (A: acquisition use cases, SE: software engineering use cases)
Use cases in which an LLM’s mistakes would be highly consequential and difficult to identify pose the greatest risk. “It's not that risk is bad, it's that risk needs to be managed,” advised Ivers. Organizations that approach risky use cases responsibly can still benefit from LLMs, as long as the cost to find and fix their mistakes is lower than the cost of a human doing the whole job alone.
The white paper goes on to identify five concerns that are relevant to all LLM use cases: correctness, disclosure of information, usability, performance, and trust. The paper provides sample questions to determine a concern’s significance and maps concerns to mitigating tactics. It also sketches each tactic’s cost and whether it centers on technical interventions, human actions, or both. “This is a human-AI partnership, and you can help both sides of that equation,” said Ivers.
In a race for capability, research on the technical aspects of LLMs abounds. “We’re looking at this at a higher, earlier level,” said Ivers. “Does it make sense to try an LLM in the first place? How do you put safeguards around yourself so that you're using it appropriately, protecting your data, not wasting your time, and producing conclusions you know are trustworthy? These are the questions we tried to help organizations answer for themselves.”
The paper concludes with examples of how organizations might take an idea for how to use an LLM, clarify the use case, identify concerns, design a workflow with tactics to address the concerns, and assess the suitability of the LLM solution.
Ivers emphasized that the white paper is a starting point based on the SEI’s experience working with government software engineering and acquisitions organizations. It offers an organized way for decision makers to responsibly consider when to use the rapidly changing technology within their own unique contexts—before investing many resources. “LLMs are going to move quickly, but the need to assess suitability is going to stay with us for a while,” he said.
Download Assessing Opportunities for LLMs in Software Engineering and Acquisition. Organizations that have tried the practices described in the paper can give feedback at info@sei.cmu.edu. Learn more about the SEI’s research on LLMs in the SEI Digital Library.

