Harnessing the Power of Large Language Models For Economic and Social Good: Foundations


PUBLISHED IN
Artificial Intelligence EngineeringIn his 2016 book, The Fourth Industrial Revolution, Klaus Schwab, the founder of the World Economic Forum, predicted the advent of the next technological revolution, underpinned by artificial intelligence (AI). He argued that, like its predecessors, the AI revolution would wield global socio-economic repercussions. Schwab’s writing was prescient. In November 2022, OpenAI released ChatGPT, a large language model (LLM) embedded with a conversation agent. The reception was phenomenal, with more than 100 million people accessing it during the first two months. Not only did ChatGPT garner widespread personal use, but hundreds of corporations promptly incorporated it and other LLMs to optimize their processes and to enable new products. In this blog post, adapted from our recent whitepaper, we examine the capabilities and limitations of LLMs. In a future post, we will present four case studies that explore potential applications of LLMs.
Despite the consensus that this technology revolution will have global consequences, experts differ on whether the impact will be positive or negative. On one hand, OpenAI’s stated mission is to create systems that benefit all of humanity. On the other hand, following the release of ChatGPT, more than a thousand researchers and technology leaders signed an open letter calling for a six-month hiatus on the development of such systems out of concern for societal welfare.
As we navigate the fourth industrial revolution, we find ourselves at a juncture where AI, including LLMs, is reshaping sectors. But with new technologies come new challenges and risks. In the case of LLMs, these include disuse—the untapped potential of opportune LLM applications; misuse—dependence on LLMs where their usage may be unwarranted; and abuse—exploitation of LLMs for malicious intent. To harness the advantages of LLMs while mitigating potential harms, it is imperative to address these issues.
This post begins by describing the fundamental principles underlying LLMs. We then delve into a range of practical applications, encompassing data science, training and education, research, and strategic planning. Our objective is to demonstrate high leverage use-cases and identify strategies to curtail misuse, abuse, and disuse, thus paving the way for more informed and effective use of this transformative technology.
The Rise of GPT
At the heart of ChatGPT is a type of LLM called a generative pretrained transformer (GPT). GPT-4 is the fourth in a series of GPT foundational models tracing back to 2018. Like its predecessor, GPT-4 can accept text inputs, such as questions or requests, and produce written responses. Its competencies reflect the massive corpora of data that it was trained with. GPT-4 exhibits human-level performance on academic and professional benchmarks including the Uniform Bar Exam, LSAT, SAT, GRE, and AP subject tests. Moreover, GPT-4 performs well on computer coding problems, common-sense reasoning, and practical tasks that require synthesizing information from many different sources. GPT-4 outperforms its predecessor in all these areas. Even more significantly, GPT-4 is multimodal, meaning that it can accept both text and image inputs. This capability allows GPT-4 to be applied to entirely new problems.
OpenAI facilitated public access to GPT-4 via a chatbot named ChatGPT Plus, offering no-code options for utilizing GPT-4. They further extended its reach by releasing a GPT-4 plugin, providing low-code options for integrating it into business applications. These moves by OpenAI have significantly lowered the barriers to adopting this transformative technology. Concurrently, the emergence of open-source GPT-4 alternatives such as LLaMA and Alpaca has catalyzed widespread experimentation and prototyping.
What are LLMs?
Although GPT-4 is new, language models are not. The complexity and richness of language is one of the distinguishing traits of human cognition. For this reason, AI researchers have long tried to emulate human language using computers. Indeed, natural language processing (NLP) can be traced to the origins of AI. In the 1950 article “Computing Machinery and Intelligence,” Alan Turning included automated generation and understanding of human language as a criterion for AI.
In the years since, NLP has undergone multiple paradigm shifts. Early work on symbolic NLP relied on hand-crafted rules. This reliance gave way to statistical NLP in the 1990s, which used machine learning to infer systems of language much as humans do. Advances in computing hardware and algorithms led to neural NLP in the 2010s. The family of methods used for neural NLP—collectively known as deep learning—are more flexible and expressive than ones used for statistical NLP. Further advances in deep learning, along with the application of these methods to datasets several orders of magnitude larger than what was previously possible, have now allowed pre-trained LLMs to meet the criterion issued by Turing in his seminal work on AI.
Fundamentally, today’s language models share an objective of historic NLP approaches—to predict the next word(s) in a sequence. This allows the model to ‘score’ the probability of different combinations of words making up sentences. In this way, language models can respond to human prompts in syntactically and semantically correct ways.
Consider the sentence, “A green frog nestled in a tree, blending in with nature’s green tapestry.” By merging repeated words, it is possible to create a graph of transition probabilities; that is, the probability of each word given the previous one (Figure 1).
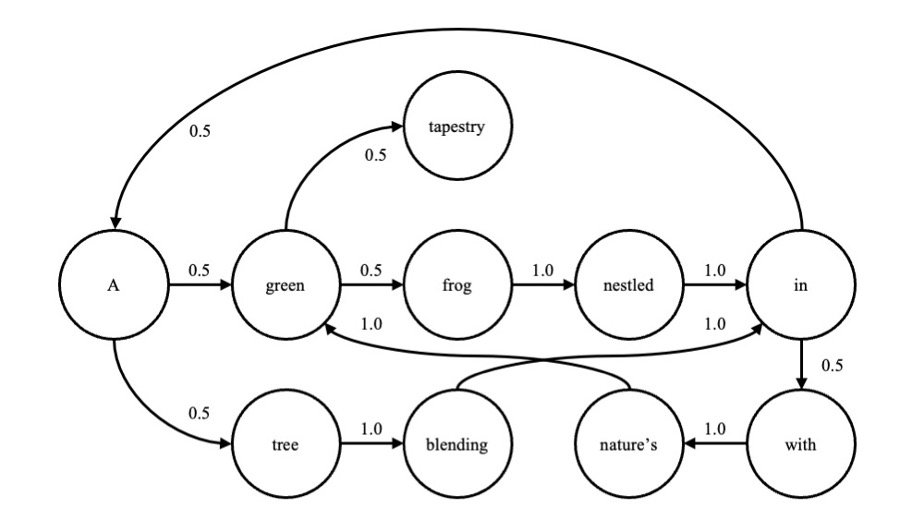
The graph can be expressed as
P(xn|xn-1).
These transition probabilities can be directly approximated from a large corpus of text. Of course, the probability of each word depends on more than just the previous one. A more complete model would calculate the probability given the previous n words. For example, for n = 10, this can be expressed as
P(xn|xn-1, xn-2, xn-3, xn-4, xn-5, xn-6, xn-7, xn-8, xn-9, xn-10).
Herein lies the challenge. As the length of the sequence increases, the transition matrix becomes intractably large. Moreover, only a small fraction of possible combinations of words has occurred or will ever occur.
Neural networks are universal function approximators. Given enough hidden layers and units, a neural network can learn to approximate an arbitrarily complex function, including functions like the one shown above. This property of neural networks has led to their use in LLMs.
Components of an LLM
Figure 2 shows major components of GPT-3, an exemplar LLM embedded in the conversational agent ChatGPT. We discuss each of these components in turn.
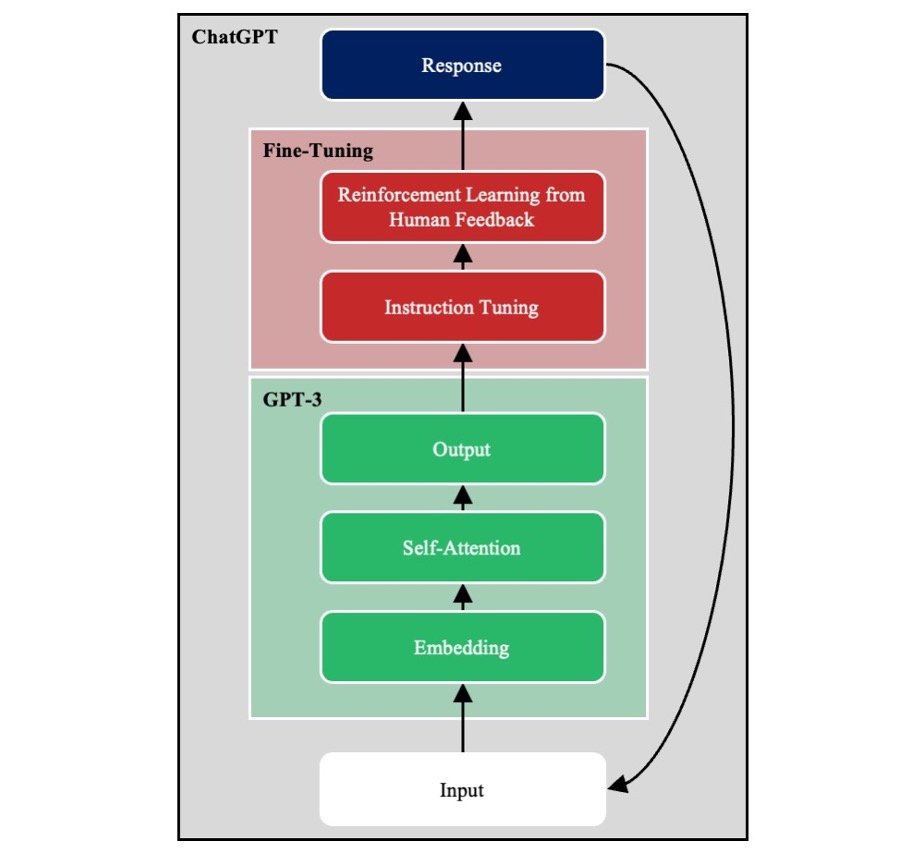
Deep Neural Network
GPT-3 is a deep neural network (DNN). Its input layer takes a passage of text broken down into word-level tokens, and its output layer returns the probabilities of all possible words appearing next. The input is transformed across a series of hidden layers to produce the output.
GPT-3 is trained using self-supervised learning. Passages from the training corpus are given as input with the final word masked, and the model must predict the masked word. Because self-supervised learning does not require labeled outputs, it allows models to be trained on vastly more data than would be possible using supervised learning.
Text Embeddings
The English language alone contains hundreds of thousands of words. GPT-3, like most other NLP models, projects word tokens onto embeddings. An embedding is a high-dimensional numeric vector that represents a word. At first glance, it may seem costly to represent each word as a vector of hundreds of numeric elements. In fact, this process compresses the input from hundreds of thousands of words to the hundreds of dimensions that comprise the embedding space. Embeddings reduce the number of downstream model weights that must be learned. Moreover, they preserve similarities between words. Thus, the words Internet and web are closer to one another in the embedding space than to the word aircraft.
Self-Attention
GPT-3 is a transformer architecture, meaning that it uses self-attention. Consider the two sentences, “The investor went to the bank” and “The bear went to the bank.” The meaning of bank depends on whether the second word is investor or bear. To interpret the final word, the model must relate it to other words contained in the sentence.
Following the introduction of the transformer architecture in 2017, self-attention has become the preferred way to capture long-range dependencies in language.[1] Self-attention copies the numeric vectors representing each word. Then, using a set of learned attentional weights, it adjusts the values for words based on the surrounding ones (i.e., context). For example, self-attention shifts the numeric representation of bank toward a financial institution in the first sentence, and it shifts it toward a river in the second sentence.
Autoregression
GPT is an autoregressive model (i.e., it is trained to predict the next word in a passage). Other LLMs are trained to predict randomly masked words masked within the body of the passage. The choice between autoregression and masking depends in part on the goal of the LLM.
With one slight adjustment, an autoregressive model can be used for natural language generation. During inference, GPT-3 is run multiple times. At each timestep, the output from the previous timestep is appended to the input, and GPT-3 is run again. In this way, GPT-3 completes its own utterances.
Instruction Tuning
GPT-3 is trained to complete passages. Consequently, when GPT-3 receives the prompt, Write an essay on emerging technologies that will transform manufacturing, GPT-3 may respond, The essay must contain 500 words. This response would be expected if the training set included descriptions of college assignments. The issue is that sentence completion is not obviously aligned with the human intent of question answering.
To overcome this limitation, GPT-3 is augmented with instruction tuning. Specifically, a group of human experts create pairs of prompts and idealized responses. This new training set is used for supervised fine-tuning (SFT). SFT better aligns GPT-3 with human intentions.
Reinforcement Learning from Human Feedback
Following SFT, additional fine-tuning is performed using reinforcement learning from human feedback (RLHF). In short, GPT-3 generates multiple possible responses to a prompt, which human raters rank from best to worst. These data are used to create a reward model that predicts the goodness of model responses. The reward model is then used to train GPT-3 at scale to produce responses better aligned with human intent.
The most direct application of SFT and RLHF is to shift GPT-3 from sentence completion to question answering. However, system designers have other objectives, such as minimizing the use of bias language. By modeling appropriate responses with SFT, and by downvoting inappropriate ones with RLHF, designers can align GPT-3 to other objectives, such as removing bias or bigoted responses.
Engineered and Emergent Abilities of LLMs
A comprehensive evaluation of GPT shows that it frequently produces syntactically and semantically correct responses across a wide range of text and computer programming prompts. Thus, it can encode, retrieve, and apply pre-existing knowledge, and it can communicate that knowledge in syntactically correct ways.
More surprisingly, LLMs like GPT-3 show unanticipated emergent abilities.
- in-context learning—GPT-3 considers the preceding conversation to generate responses that are aligned with the given context. Thus, depending on the preceding conversation, GPT-3 can respond to the same prompt in very different ways, which is called in-context learning because GPT-3 modifies its behavior without requiring changes to its pre-trained weights.
- instruction following—Instruction following is an example of in-context learning. Consider the two prompts, Write a poem; include flour, egg, and sugar and Write a receipt; include flour, eggs, and sugar. Instruction establishes context, which shapes GPT-3’s response. In this way, GPT-3 can perform new tasks without re-training.
- few-shot learning—Few-shot learning is another example of in-context learning. The user provides examples of the types and form of desired outputs. Examples establish context, which again allows GPT-3 to generalize to new tasks without re-training.
Prompt engineering refers to issuing prompts in a certain way to evoke different types of response. It is another example of in-context learning. However, the use of SFT and RLHF in GPT-3 reduces the need for prompt engineering for common tasks, such as question answering.
Looking Ahead
The AI revolution represents an expansive evolution of machine automation, encompassing both routine and non-routine tasks. Parasuraman’s cautionary notes on automation’s misuse and abuse extend their relevance to AI, including LLMs.
Within our discussion, we hinted at the potential for misuse of LLMs. For example, human users may inadvertently accept factually incorrect responses from ChatGPT. Moreover, LLMs can be subject to abuse. For example, adversaries may use them to generate misinformation or to unleash new forms of malware. To address these risks, a comprehensive risk mitigation plan must encompass strategic system design, end-user training, testing and evaluation, as well as robust defense mechanisms. However, although risks can be reduced, they cannot be eliminated.
Parasuraman also cautioned against disuse, or the failure to adopt automation when it would be beneficial to do so. Once again, this warning extends to AI. As the AI revolution unfolds, therefore, we must remain mindful of potential harms, while equally recognizing and embracing the remarkable potential for societal benefits.
In the next post in thie series, we will explore four case studies that present powerful opportunities for LLMs to augment human intelligence.
Additional Resources
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
OpenAI. (2023). GPT-4 Technical report.
Parasuraman, R., & Riley, V. (1997). Humans and automation: Use, misuse, disuse, abuse. Human factors, 39(2), 230-253.
Schwab, K. (2017). The Fourth Industrial Revolution. Crown Publishing, New York, NY
Turing, A. (1950). Computing Machinery and Intelligence. Mind, LI(236), 433–460.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
The Messy Middle of Large Language Models with Jay Palat and Rachel Dzombak
Written By




More By The Authors
More In Artificial Intelligence Engineering
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed