A Framework for Detection in an Era of Rising Deepfakes

PUBLISHED IN
Cybersecurity EngineeringThis post is also written by Vedha Avali, Genavieve Chick, and Kevin Kurian.
Every day, new examples of deepfakes are surfacing. Some are meant to be entertaining or funny, but many are meant to deceive. Early deepfake attacks targeted public figures. However, businesses, government organizations, and healthcare entities have also become prime targets. A recent analysis found that slightly more than half of businesses in the United States and the United Kingdom have been targets of financial scams powered by deepfake technology, with 43 percent falling victim to such attacks. On the national security front, deepfakes can be weaponized, enabling the dissemination of misinformation, disinformation, and malinformation (MDM).
It is difficult, but not impossible, to detect deepfakes with the aid of machine intelligence. However, detection methods must continue to evolve as generation techniques become increasingly sophisticated. To counter the threat posed by deepfakes, our team of researchers in the SEI’s CERT Division has developed a software framework for forgery detection. In this blog post we detail the evolving deepfake landscape, along with the framework we developed to combat this threat.
The Evolution of Deepfakes
We define deepfakes as follows:
Deepfakes use deep neural networks to create realistic images or videos of people saying or doing things they never said or did in real life. The technique involves training a model on a large dataset of images or videos of a target person and then using the model to generate new content that convincingly imitates the person’s voice or facial expressions.
Deepfakes are part of a growing body of generative AI capabilities that can be manipulated for deceit in information operations. As the AI capabilities improve, the methods of manipulating information become ever harder to detect. They include the following:
- Audio manipulation digitally alters aspects of an audio recording to modify its meaning. This can involve changing the pitch, duration, volume, or other properties of the audio signal. In recent years, deep neural networks have been used to create highly realistic audio samples of people saying things they never actually said.
- Image manipulation is the process of digitally altering aspects of an image to modify its appearance and meaning. This can involve changing the appearance of objects or people in an image. In recent years, deep neural networks have been used to generate entirely new images that are not based on real-world objects or scenes.
- Text generation involves the use of deep neural networks, such as recurrent neural networks and transformer-based models, to produce authentic-looking text that seems to have been written by a human. These techniques can replicate the writing and speaking style of individuals, making the generated text appear more believable.
A Growing Problem
Figure 1 below shows the annual number of reported or identified deepfake incidents based on data from the AIAAIC (AI, Algorithmic, and Automation Incidents and Controversies) and the AI Incident Database. From 2017, when deepfakes first emerged, to 2022, there was a gradual increase in incidents. However, from 2022 to 2023, there was a nearly five-fold increase. The projected number of incidents for 2024 exceeds that of 2023, suggesting that the heightened level of attacks seen in 2023 is likely to become the new norm rather than an exception.
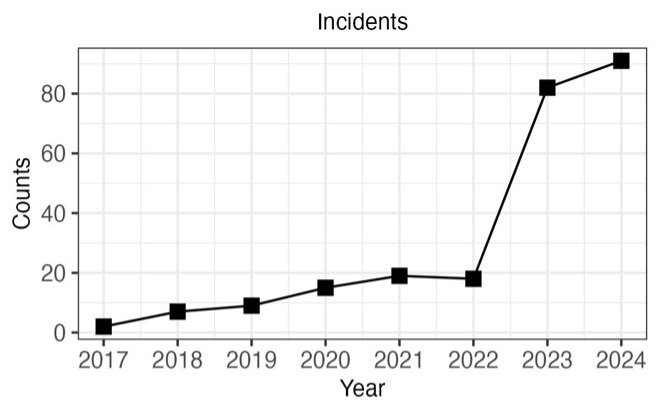
Most incidents involved public misinformation (60 percent), followed by defamation (15 percent), fraud (10 percent), exploitation (8 percent), and identity theft (7 percent). Political figures and organizations were the most frequently targeted (54 percent), with additional attacks occurring in the media sector (28 percent), industry (9 percent), and the private sector (8 percent).
An Evolving Threat
Figure 2 below shows the cumulative number of academic publications on deepfake generation from the Web of Science. From 2017 to 2019, there was a steady increase in publications on deepfake generation. The publication rate surged during 2019 and has remained at the elevated level ever since. The figure also shows the cumulative number of open-source code repositories for deepfake generation from GitHub. The number of repositories for creating deepfakes has increased along with the number of publications. Thus, deepfake generation methods are more capable and more available than ever before in the past.
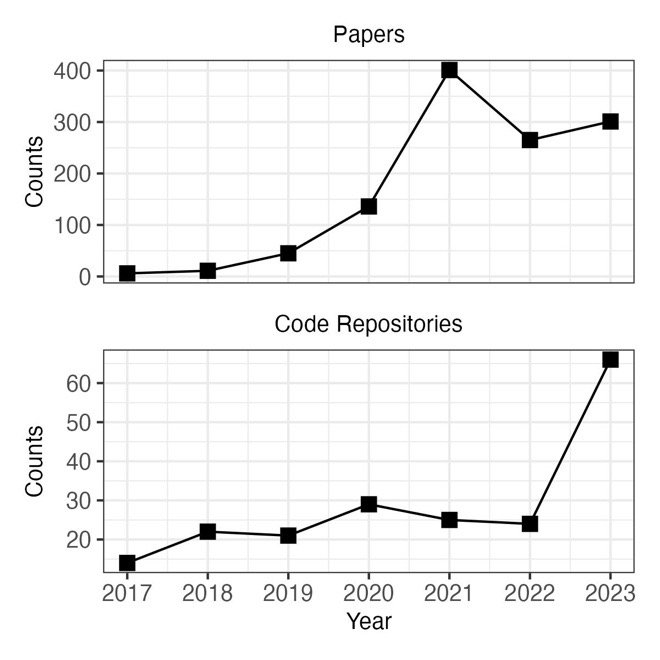
Across this research, four foundational architectures for deepfake generation have emerged:
- Variational auto encoders (VAE). A VAE consists of an encoder and a decoder. The encoder learns to map inputs from the original space (i.e., an image) to a lower-dimensional latent representation, while the decoder learns to reconstruct a simulacrum of the original input from this latent space. In deepfake generation, an input from the attacker is processed by the encoder, and the decoder—trained with footage of the victim—reconstructs the source signal to match the victim's appearance and characteristics. Unlike its precursor, the autoencoder (AE), which maps inputs to a fixed point in the latent space, the VAE maps inputs to a probability distribution. This allows the VAE to generate smoother, more natural outputs with fewer discontinuities and artifacts.
- Generative adversarial networks (GANs). GANs consist of two neural networks, a generator and a discriminator, competing in a zero-sum game. The generator creates fake data, such as images of faces, while the discriminator evaluates the authenticity of the data created by the generator. Both networks improve over time, leading to highly realistic generated content. Following training, the generator is used to produce artificial faces.
- Diffusion models (DM). Diffusion refers to a method where data, such as images, are progressively corrupted by adding noise. A model is trained to sequentially denoise these blurred images. Once the denoising model has been trained, it can be used for generation by starting from an image composed entirely of noise, and gradually refining it through the learned denoising process. DMs can produce highly detailed and photorealistic images. The denoising process can also be conditioned on text inputs, allowing DMs to produce outputs based on specific descriptions of objects or scenes.
- Transformers. The transformer architecture uses a self-attention mechanism to clarify the meaning of tokens based on their context. For example, the meaning of words in a sentence. Transformers effective for natural language processing (NLP) because of sequential dependencies present in language. Transformers are also used in text-to-speech (TTS) systems to capture sequential dependencies present in audio signals, allowing for the creation of realistic audio deepfakes. Additionally, transformers underlie multimodal systems like DALL-E, which can generate images from text descriptions.
These architectures have distinct strengths and limitations, which have implications for their use. VAEs and GANs remain the most widely used methods, but DMs are increasing in popularity. These models can generate photorealistic images and videos, and their ability to incorporate information from text descriptions into the generation process gives users exceptional control over the outputs. Additionally, DMs can create realistic faces, bodies, or even entire scenes. The quality and creative control allowed by DMs enable more tailored and sophisticated deepfake attacks than previously possible.
Legislating Deepfakes
To counter the threat posed by deepfakes and, more fundamentally, to define the boundaries for their legal use, federal and state governments have pursued legislation to regulate deepfakes. Since 2019, 27 deepfake-related pieces of federal legislation have been introduced. About half of these involve how deepfakes may be used, focusing on the areas of adult content, politics, intellectual property, and consumer protection. The remaining bills call for reports and task forces to study the research, development, and use of deepfakes. Unfortunately, attempts at federal legislation are not keeping pace with advances in deepfake generation methods and the growth of deepfake attacks. Of the 27 bills that have been introduced, only five have been enacted into law.
At the state level, 286 bills were introduced during the 2024 legislative session. These bills predominantly focus on regulating deepfakes in the areas of adult content, politics, and fraud, and they sought to strengthen deepfake research and public literacy.
These legislative actions represent progress in establishing boundaries for the appropriate use of deepfake technologies and penalties for their misuse. However, for these laws to be effective, authorities must be capable of detecting deepfake content—and this capability will depend on access to effective tools.
A New Framework for Detecting Deepfakes
The national security risks associated with the rise in deepfake generation techniques and use have been recognized by both the federal government and the Department of Defense. Attackers can use these techniques to spread MDM with the intent of influencing U.S. political processes or undermining U.S. interests. To address this issue, the U.S. government has implemented legislation to enhance awareness and comprehension of these threats. Our team of researchers in the SEI’s CERT Division have developed a tool for establishing the authenticity of multimedia assets, including images, video, and audio. Our tool is built on three guiding principles:
- Automation to enable deployment at scale for tens of thousands of videos
- Mixed-initiative to harness human and machine intelligence
- Ensemble techniques to allow for a multi-tiered detection strategy
The figure below illustrates how these principles are integrated into a human-centered workflow for digital media authentication. The analyst can upload one or more videos featuring an individual. Our tool compares the person in each video against a database of known individuals. If a match is found, the tool annotates the individual's identity. The analyst can then choose from multiple deepfake detectors, which are trained to identify spatial, temporal, multimodal, and physiological abnormalities. If any detectors find abnormalities, the tool flags the content for further review.
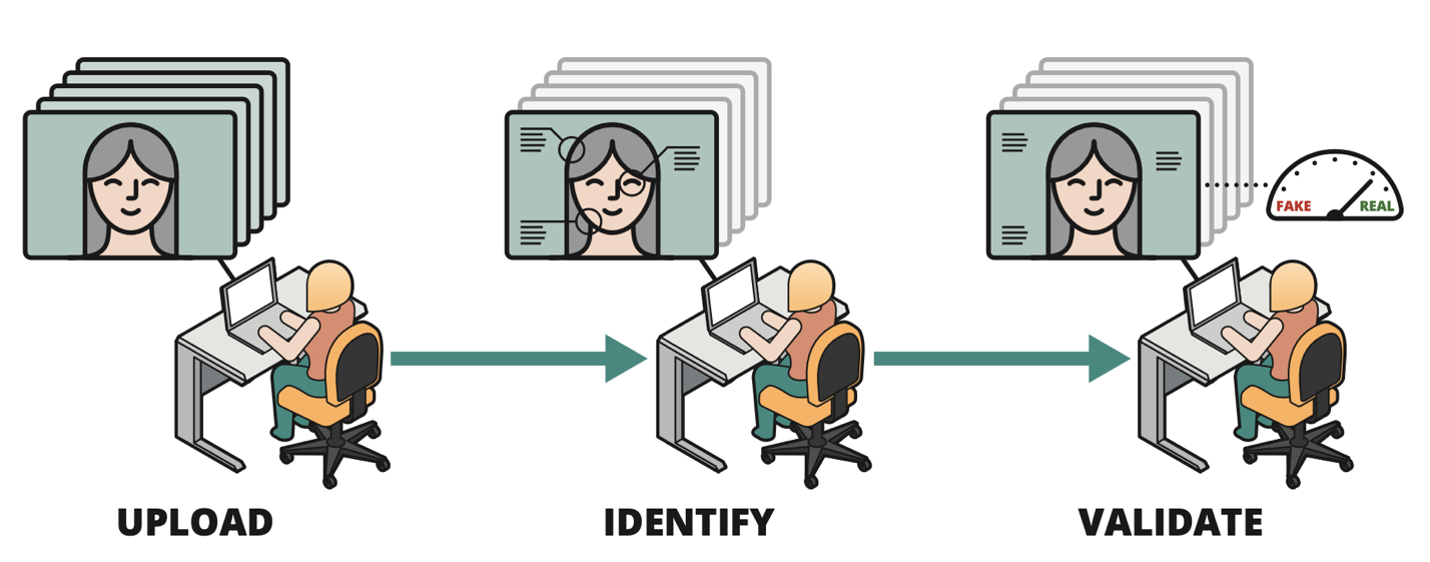
The tool enables rapid triage of image and video data. Given the vast amount of footage uploaded to multimedia sites and social media platforms daily, this is an essential capability. By using the tool, organizations can make the best use of their human capital by directing analyst attention to the most critical multimedia assets.
Work with Us to Mitigate Your Organization's Deepfake Threat
Over the past decade, there have been remarkable advances in generative AI, including the ability to create and manipulate images and videos of human faces. While there are legitimate applications for these deepfake technologies, they can also be weaponized to deceive individuals, companies, and the public.
Technical solutions like deepfake detectors are needed to protect individuals and organizations against the deepfake threat. But technical solutions are not enough. It is also crucial to increase people’s awareness of the deepfake threat by providing industry, consumer, law enforcement, and public education.
As you develop a strategy to protect your organization and people from deepfakes, we are ready to share our tools, experiences, and lessons learned.
Additional Resources
Read the SEI blog post How Easy Is It to Make and Detect a Deepfake with Catherine Bernaciak and Dominic Ross.
View/listen to the SEI podcast, A Dive into Deepfakes, with Shannon Gallagher and Dominic Ross.
View the SEI webcast, What are Deepfakes and How Can We Detect Them, with Shannon Gallagher and Dominic Ross.
Written By

More By The Author
More In Cybersecurity Engineering
PUBLISHED IN
Cybersecurity EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Cybersecurity Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed