3 Recommendations for Machine Unlearning Evaluation Challenges


PUBLISHED IN
Artificial Intelligence EngineeringMachine learning (ML) models are becoming more deeply integrated into many products and services we use every day. This proliferation of artificial intelligence (AI)/ML technology raises a host of concerns about privacy breaches, model bias, and unauthorized use of data to train models. All of these areas point to the importance of having flexible and responsive control over the data a model is trained on. Retraining a model from scratch to remove specific data points, however, is often impractical due to the high computational and financial costs involved. Research into machine unlearning (MU) aims to develop new methods to remove data points efficiently and effectively from a model without the need for extensive retraining. In this post, we discuss our work on machine unlearning challenges and offer recommendations for more robust evaluation methods.
Machine Unlearning Use Cases
The importance of machine unlearning cannot be understated. It has the potential to address critical challenges, such as compliance with privacy laws, dynamic data management, reversing unintended inclusion of unlicensed intellectual property, and responding to data breaches.
- Privacy protection: Machine unlearning can play a crucial role in enforcing privacy rights and complying with regulations like the EU’s GDPR (which includes a right to be forgotten for users) and the California Consumer Privacy Act (CCPA). It allows for the removal of personal data from trained models, thus safeguarding individual privacy.
- Security improvement: By removing poisoned data points, machine unlearning could enhance the security of models against data poisoning attacks, which aim to manipulate a model's behavior.
- Adaptability enhancement: Machine unlearning at broader scale could help models stay relevant as data distributions change over time, such as evolving customer preferences or market trends.
- Regulatory compliance: In regulated industries like finance and healthcare, machine unlearning could be crucial for maintaining compliance with changing laws and regulations.
- Bias mitigation: MU could offer a way to remove biased data points identified after model training, thus promoting fairness and reducing the risk of unfair outcomes.
Machine Unlearning Competitions
The growing interest in machine unlearning is evident from recent competitions that have drawn significant attention from the AI community:
- NeurIPS Machine Unlearning Challenge: This competition attracted more than 1,000 teams and 1,900 submissions, highlighting the widespread interest in this field. Interestingly, the evaluation metric used in this challenge was related to differential privacy, highlighting an important connection between these two privacy-preserving techniques. Both machine unlearning and differential privacy involve a trade-off between protecting specific information and maintaining overall model performance. Just as differential privacy introduces noise to protect individual data points, machine unlearning may cause a general “wooliness” or decrease in precision for certain tasks as it removes specific information. The findings from this challenge provide valuable insights into the current state of machine unlearning techniques.
- Google Machine Unlearning Challenge: Google’s involvement in promoting research in this area underscores the importance of machine unlearning for major tech companies dealing with vast amounts of user data.
These competitions not only showcase the diversity of approaches to machine unlearning but also help in establishing benchmarks and best practices for the field. Their popularity also evince the rapidly evolving nature of the field. Machine unlearning is very much an open problem. While there is optimism about machine unlearning being a promising solution to many of the privacy and security challenges posed by AI, current machine unlearning methods are limited in their measured effectiveness and scalability.
Technical Implementations of Machine Unlearning
Most machine unlearning implementations involve first splitting the original training dataset into data (Dtrain) that should be kept (the retain set, or Dr) and data that should be unlearned (the forget set, or Df), as shown in Figure 1.
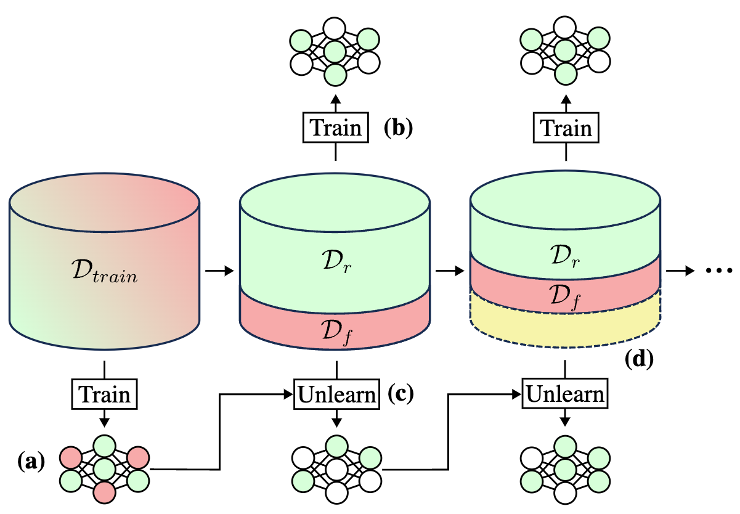
Next, these two sets are used to alter the parameters of the trained model. There are a variety of techniques researchers have explored for this unlearning step, including:
- Fine-tuning: The model is further trained on the retain set, allowing it to adapt to the new data distribution. This technique is simple but can require lots of computational power.
- Random labeling: Incorrect random labels are assigned to the forget set, confusing the model. The model is then fine-tuned.
- Gradient reversal: The sign on the weight update gradients is flipped for the data in the forget set during fine-tuning. This directly counters previous training.
- Selective parameter reduction: Using weight analysis techniques, parameters specifically tied to the forget set are selectively reduced without any fine-tuning.
The range of different techniques for unlearning reflects the range of use cases for unlearning. Different use cases have different desiderata—in particular, they involve different tradeoffs between unlearning effectiveness, efficiency, and privacy concerns.
Evaluation and Privacy Challenges
One difficulty of machine unlearning is evaluating how well an unlearning technique simultaneously forgets the specified data, maintains performance on retained data, and protects privacy. Ideally a machine unlearning method should produce a model that performs as if it were trained from scratch without the forget set. Common approaches to unlearning (including random labeling, gradient reversal, and selective parameter reduction) involve actively degrading model performance on the datapoints in the forget set, while also trying to maintain model performance on the retain set.
Naïvely, one could assess an unlearning method on two simple objectives: high performance on the retain set and poor performance on the forget set. However, this approach risks opening another privacy attack surface: if an unlearned model performs particularly poorly for a given input, that could tip off an attacker that the input was in the original training dataset and then unlearned. This type of privacy breach, called a membership inference attack, could reveal important and sensitive data about a user or dataset. It is vital when evaluating machine unlearning methods to test their efficacy against these sorts of membership inference attacks.
In the context of membership inference attacks, the terms "stronger" and "weaker" refer to the sophistication and effectiveness of the attack:
- Weaker attacks: These are simpler, more straightforward attempts to infer membership. They might rely on basic information like the model's confidence scores or output probabilities for a given input. Weaker attacks often make simplifying assumptions about the model or the data distribution, which can limit their effectiveness.
- Stronger attacks: These are more sophisticated and utilize more information or more advanced techniques. They might:
- use multiple query points or carefully crafted inputs
- exploit knowledge about the model architecture or training process
- utilize shadow models to better understand the behavior of the target model
- combine multiple attack strategies
- adapt to the specific characteristics of the target model or dataset
Stronger attacks are generally more effective at inferring membership and are thus harder to defend against. They represent a more realistic threat model in many real-world scenarios where motivated attackers might have significant resources and expertise.
Evaluation Recommendations
Here in the SEI AI division, we’re working on developing new machine unlearning evaluations that more accurately mirror a production setting and subject models to more realistic privacy attacks. In our recent publication “Gone But Not Forgotten: Improved Benchmarks for Machine Unlearning,” we offer recommendations for better unlearning evaluations based on a review of the existing literature, propose new benchmarks, reproduce several state-of-the-art (SoTA) unlearning algorithms on our benchmarks, and compare outcomes. We evaluated unlearning algorithms for accuracy on retained data, privacy protection with regard to the forget data, and speed of accomplishing the unlearning process.
Our analysis revealed large discrepancies between SoTA unlearning algorithms, with many struggling to find success in all three evaluation areas. We evaluated three baseline methods (Identity, Retrain, and Finetune on retain) and five state-of-the-art unlearning algorithms (RandLabel, BadTeach, SCRUB+R, Selective Synaptic Dampening [SSD], and a combination of SSD and finetuning).
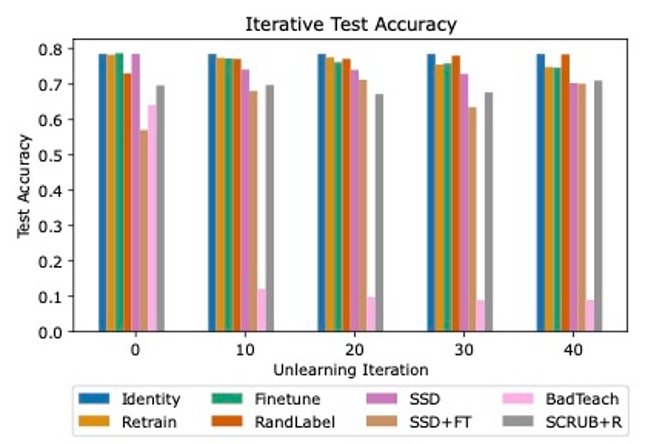
In line with previous research, we found that some methods that successfully defended against weak membership inference attacks were completely ineffective against stronger attacks, highlighting the need for worst-case evaluations. We also demonstrated the importance of evaluating algorithms in an iterative setting, as some algorithms increasingly hurt overall model accuracy over unlearning iterations, while some were able to consistently maintain high performance, as shown in Figure 2.
Based on our assessments, we recommend that practitioners:
1) Emphasize worst-case metrics over average-case metrics and use strong adversarial attacks in algorithm evaluations. Users are more concerned about worst-case scenarios—such as exposure of personal financial information—not average-case scenarios. Evaluating for worst-case metrics provides a high-quality upper-bound on privacy.
2) Consider specific types of privacy attacks where the attacker has access to outputs from two different versions of a model, for example, leakage from model updates. In these scenarios, unlearning can result in worse privacy outcomes because we are providing the attacker with more information. If an update-leakage attack does occur, it should be no more harmful than an attack on the base model. Currently, the only unlearning algorithms benchmarked on update-leakage attacks are SISA and GraphEraser.
3) Analyze unlearning algorithm performance over repeated applications of unlearning (that is, iterative unlearning), especially for degradation of test accuracy performance of the unlearned models. Since machine learning models are deployed in constantly changing environments where forget requests, data from new users, and bad (or poisoned) data arrive dynamically, it is critical to evaluate them in a similar online setting, where requests to forget datapoints arrive in a stream. At present, very little research takes this approach.
Looking Ahead
As AI continues to integrate into various aspects of life, machine unlearning will likely become an increasingly vital tool—and complement to careful curation of training data—for balancing AI capabilities with privacy and security concerns. While it opens new doors for privacy protection and adaptable AI systems, it also faces significant hurdles, including technical limitations and the high computational cost of some unlearning methods. Ongoing research and development in this field are essential to refine these techniques and ensure they can be effectively implemented in real-world scenarios.
Additional Resources
"Gone but Not Forgotten: Improved Benchmarks for Machine Unlearning" by Keltin Grimes, Collin Abidi, Cole Frank, and Shannon Gallagher.
Written By




More By The Authors
More In Artificial Intelligence Engineering
PUBLISHED IN
Artificial Intelligence EngineeringGet updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Artificial Intelligence Engineering
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed