When Your Software’s “Check Engine” Light Is On: Identifying Design Problems that Impact Software Failure

In the fast-moving world of Agile and DevSecOps, neglecting fundamental maintenance activities will likely hinder delivery of value in the long run. Although the cost of system maintenance represents a large proportion of the budget of most organizations that use software systems, insufficient maintenance may lead to various problems, including
- a reduction in software quality as errors are inadvertently introduced during the development process
- the inability to deliver customer value if a repair or enhancement cannot be delivered on time
Insufficient maintenance can cause a software system’s code and its underlying design to decay over time. This decay can make system maintenance cumbersome or render a system that cannot adapt to new business needs. Fortunately, there are proven approaches to identify and understand design problems and improve software performance. Just as even the most reliable car needs a routine oil change and tune-up to keep running efficiently, software development processes, design, and architecture should be routinely revisited and optimized to remain effective.
The “squeaky parts” that we are looking to detect are design problems that may potentially decrease performance or hinder maintenance. This blog post summarizes an effective roadmap for detecting design problems that can be used to improve software development and performance.
What Is a Design Problem?
A design problem results from one or more inappropriate design decisions that negatively impact quality attributes. The development and maintenance of software systems require developers to pay special attention to non-functional requirements such as maintainability, extensibility, availability, and performance. Design decisions affect each non-functional requirement in a positive or negative manner. Moreover, the existence of design problems may necessitate re-engineering or discontinuing the system.
Fundamental Design Principles
Foundational to this discussion is the premise that high performing applications follow established design principles. Let’s discuss two such principles: design rule theory and design rule hierarchy.
- Design rule theory asserts that good design is supported by consistent, compatible design rules and truly independent modules. Carliss Y. Baldwin and Kim B. Clark write in Design Rules, Vol. 1: The Power of Modularity
Software should be structured by design rules and independent modules. In a software system, design rules are often manifested as the important design decisions, which decouple the system into independent modules. A design rule is typically manifested as an interface or abstract class.
- Design rule hierarchy asserts that components of software should exist in a clear hierarchy of dependencies. Good design is supported by clean, clear hierarchies. In Architecture Anti-Patterns: Automatically Detectable Violations of Design Principles, Mo and colleagues write:
Files in the same layer are decoupled into a set of modules that are mutually independent from each other. Thus, changes, addition, even replacement to a module will not influence other modules within the same layer. Accordingly, independent modules in the bottom layer of a design rule hierarchy are most valuable, because changes to these modules will not affect the rest of the system.
Identifying Design Problems
Identifying design problems can be a complex task. For example, design documentation is often unavailable or outdated. Developers are then forced to analyze several elements in the source code to identify each design problem. Moreover, a single design problem may manifest itself as multiple symptoms scattered throughout several elements of the program. As a first step, I suggest understanding the relationships and dependencies in the program using a top-down approach.
Relationships and Dependencies
Relationships cause dependencies, and overly complex dependencies result in software that is more prone to failure. Clustering methods can be used to evaluate the modularization of a particular system.
Technical dependencies include syntactic dependencies and logical dependencies. A syntactic dependency can be a data-related dependency (e.g., a particular data structure modified by a function and used in another function) or a functional dependency (e.g., method A calls method B). These dependencies are typically discovered by analyzing (1) source code or (2) an intermediate representation, such as bytecodes or abstract syntax trees.
Logical dependencies can be subtle and harder to discover. In addition to explicit relationships, logical dependencies capture semantic or implicit relationships among source code files. An approach for identifying logical dependencies focuses on deducing dependencies among the source-code files of a system that change as part of software development.
The figures below provide an example of clustering in a program for a maze game. The design structure matrix, also known as dependency structure matrix, provides a simple and concise way to represent a complex system. A design structure matrix is a square matrix (i.e., it has an equal number of rows and columns) that shows relationships between elements in a system.
Figure 1 is an example of a design structure matrix for a maze game. Elements in the system are labeled on the vertical and horizontal edges. Each cell marked with “x” represents a pairwise dependency relation.
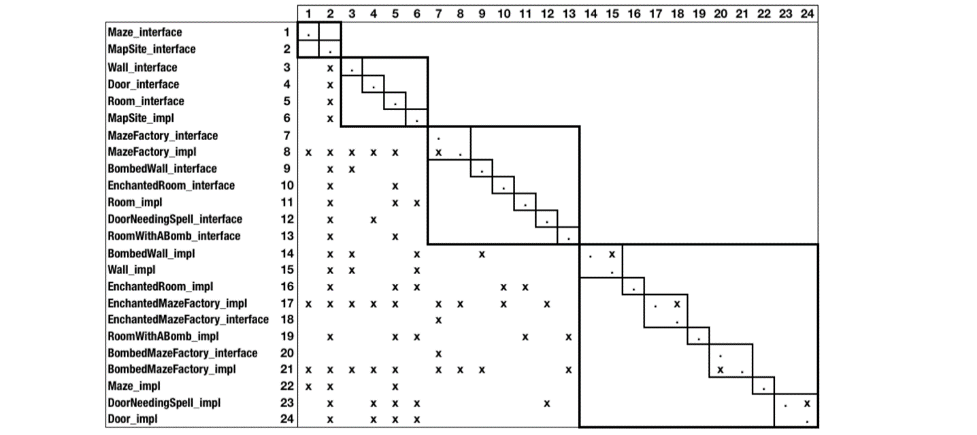
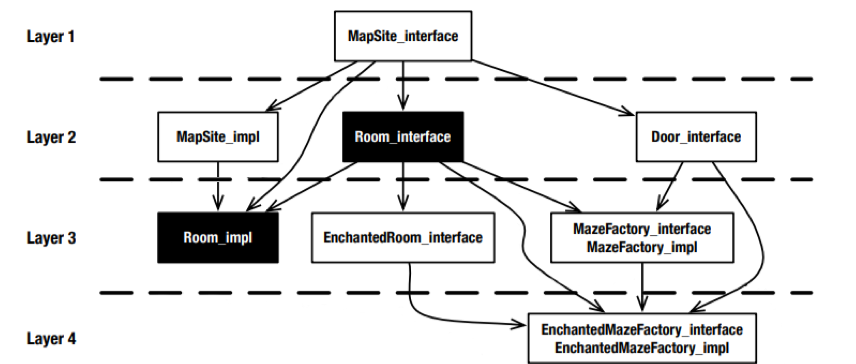
Similar to the design structure matrix, a design rule hierarchy diagram provides a quick overview of the relationships between different elements of a system. It also captures the hierarchy of dependencies by setting the elements into specific visual layers. By using such visualizations, we can begin to understand the relationships and dependencies present in our software.
Indicators of Design Problems
Indicators of software design problems include architecture antipatterns, architecture smells, and code smells. An antipattern describes a recurring situation that has a negative impact on a software project, whereas a smell is a symptom of poor design. Antipatterns include wide-ranging concerns related to project management, architecture, and development, and they generally indicate organizational and process difficulties. In the next sections, we examine architecture antipatterns, architecture smells, and code smells.
Architecture Antipatterns
Architecture antipatterns focus on design problems in the internal structure and behavior of systems. They capture the causes and characteristics of poor design from a systemwide viewpoint. Architectural antipatterns can negatively affect any system quality, while architectural smells (which we will discuss next) affect only lifecycle properties.
The following are six key architecture antipatterns to pay attention to, as excerpted from Architecture Anti-Patterns: Automatically Detectable Violations of Design Principles:
- Unstable interface—Based on design rule theory and prevailing design principles, an influential interface with many dependents should remain stable. In reality, we have observed that if influential files have high change rates, then multiple files depending on them must be changed as a consequence. When changes to an interface are not limited only to the interface, extra work and additional failure points arise.
- Modularity violation groups—Based on design rule theory, truly independent modules should evolve independently. Modules that have changed together frequently over time, as evidenced in revision history, but have no structural dependency, may be problematic. They are not truly independent as they were designed to be, impacting maintainability and resiliency.
- Unhealthy inheritance hierarchy—This antipattern includes cases where the parent class depends on one or more of its children, or the client of the hierarchy depends on both the parent class and its children. These cases undermine the objective of an inheritance hierarchy to enable polymorphism. As a result, this structure propagates bugs and changes to files that depend on this inheritance hierarchy.
- Crossing—A file that has both high fan-in and high fanout (the file is using many classes and being used by many classes), and changes often together with its dependents and the files it depends on, is often at the center of maintenance activities. This complex interdependency relationship may be easily broken.
- Clique—Circular dependency is a well-known design problem that can cause unwanted effects in software programs. Clique refers to a group of files that travel together. Files in each clique instance are tightly coupled with one or more dependency cycles.
- Package cycle—Dependency cycles between packages violate the basic design principle of forming a hierarchical structure. Changes to a file in one package often cause unexpected changes to files in other packages due to the cycle of dependencies between them. The tight coupling of the mutually dependent modules, which reduces or makes impossible the separate reuse of a single module, is problematic from a software design point of view.
Architecture Smells
Architecture smells are design problems that negatively impact system lifecycle properties, such as understandability, testability, extensibility, and reusability. Architecture smells are combinations of architectural constructs that reduce system maintainability. They may slow down the speed of software development and increase the risk of bugs in the future. Below, we highlight potentially problematic architectural smells grouped around four main categories, as excerpted from Relating Architectural Decay and Sustainability of Software Systems:
Interface-Based Architecture Smells
Four different architecture smells can be detected based on a component’s set of interfaces:
- Ambiguous interface—is an interface that offers only a single, general entry point to a system component or connector; contains a single parameter; and dispatches to different internal operations based on the content of the parameter.
- Sloppy delegation—occurs when a component delegates to another component a small amount of functionality that it could have performed itself.
- Brick functionality overload—occurs when a component performs an excessive amount of functionality.
- Lego syndrome—occurs when a component handles an extremely small amount of functionality. This smell is another indicator of inappropriate separation of concerns. Such components should be moved into another component.
Change-Based Architecture Smells
Two architecture smells reflect the reality that many parts of a code base must be updated simultaneously:
- Duplicate functionality—indicates that a component shares the same functionality with other components. Changing one instance of the functionality without changing the others may create errors. In turn, this increases complexity.
- Logical coupling—occurs when parts of different components are frequently changed together. Logical coupling may be identified, for example, by mining commit logs.
Concern-Based Architecture Smells
Two additional architecture smells are semantics-based smells that are defined and detected by using language-processing techniques, such as topic modeling:
- Scattered parasitic functionality—describes a system in which multiple components are responsible for realizing the same high-level concern.
- Concern overload—indicates that a component implements an excessive number of concerns. This directly violates the principle of separation of concerns, a software architecture design pattern/principle for separating an application into distinct sections so each section addresses a separate concern.
Dependency-Based Architecture Smells
Two final architecture smells are detected by checking how a system’s components are connected and allowed to interact:
- Dependency cycle—indicates a set of components whose links form a circular chain, causing changes to one component to possibly affect all other components in the cycle.
- Link overload—occurs when a component has interfaces involved in an excessive number of dependencies on other components, affecting the system’s isolation of changes.
Code Smells
The term code smells was first introduced in 1999. A code smell refers to code structures that intuitively appear as bad solutions and indicate possibilities for code improvements. For most code smells, there are known refactoring solutions that result in higher quality software.
In Toward a Catalogue of Architectural Bad Smells, Garcia and colleagues explain:
Code smells are implementation structures that negatively affect system lifecycle properties, such as understandability, testability, extensibility, and reusability. Code smells ultimately result in maintainability problems. Common examples of code smells include very long parameter lists and duplicated code (i.e., clones). Code smells are defined in terms of implementation-level constructs, such as methods, classes, parameters, and statements. Consequently, refactoring methods to correct code smells also operate at the implementation level (e.g., moving a method from one class to another, adding a new class, or altering the class-inheritance hierarchy).
Code smells can generally be grouped into four different categories:
- Code duplication —As Martin Fowler explains in his book, Refactoring: Improving the Design of Existing Code, “Duplicated code occurs when we have the same code structure in more than one place. As a fundamental rule of thumb, it is always better to have a unified code.”
- Classification—Classes and methods may be attempting to do too much (cover too much functionality) or may not have enough functionality to justify their existence. Parameters may be set up and used inefficiently.
- Coupling and cohesion—Coupling is the degree to which different software components depend on one another. Cohesion is the degree to which the components within a software module belong together and work well together. Low cohesion and tight coupling usually yield bad code smells and dependencies that need to be untangled.
- Delegation—Directly related to the good use of classification, too much or too little delegation may be problematic in software components.
Prioritizing Code Smells
Developers should be able to identify which code smells are actually harmful to the architecture design of a system and prioritize those fixes (i.e., which code smells can actually cause the design of a system to deviate substantially from the original architecture?). In Detecting Architecturally-Relevant Code Smells in Evolving Software Systems, Bertran conducted research to identify a set of architecturally relevant code smells and determined the correlation of code-smell patterns to architectural degeneration. Bertran’s findings suggest which code smells we should pay attention to first, as summarized in Table 1 below.
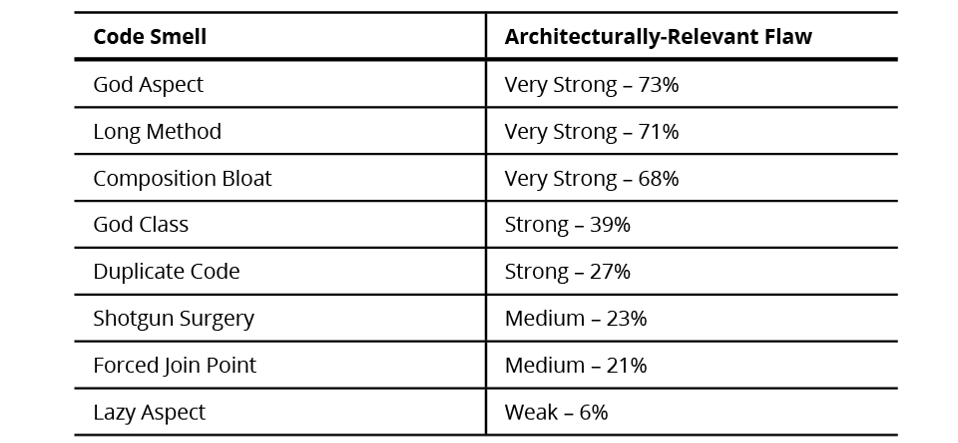
It seems fitting that code smells most strongly disruptive to the program architecture are the same as (or related to) the code smells that introduce the greatest inefficiencies at the program-execution level. This relationship points to the strong correlation between performance efficiency and good design. The god aspect and god class code smells refer to the concept of god object, which is an object that knows too much or does too much. Long method code smell is a method function or procedure that has grown too large. Composite bloat refers to the combination of various code, methods, and classes that have increased to such large proportions that they are hard to work with, which usually accumulates over time as the program evolves (and especially when nobody makes an effort to eradicate bloat). Finally, duplicated code occurs when the same code structure appears in more than one place, a gentle reminder that “As a fundamental rule of thumb, it is always better to have a unified code.”
Optimizing for Performance in the Age of DevSecOps
With CIOs reporting that 57 percent of technology budgets are allocated to business operations (i.e., day-to-day use and maintenance of business applications), it is important to ensure that those business applications are optimized for performance. In the fast-moving world of Agile and DevSecOps, it is especially important to plan for these routine maintenance activities to ensure the overall quality and longevity of your software. It is even better if software maintenance is on a timely schedule and of a preventative nature rather than corrective. Given the reality of time and resource constraints, achieving this goal can be a big effort. But just don’t wait until your software is screaming “Service due!”
Additional Resources
Learn more about the SEI’s work in DevSecOps.
Architecture Anti-patterns: Automatically Detectable Violations of Design Principles by Mo, R.; Cai, Y.; Kazman, R.; Xiao, L.; & Feng, Q.
Software Dependencies, Work Dependencies, and Their Impact on Failures by Marcelo Cataldo, Audris Mockus, Jeffrey A. Roberts, and James D. Herbsleb
Toward a Catalogue of Architectural Bad Smells by Joshua Garcia, Daniel Popescu, George Edwards, and Nenad Medvidovic
Relating Architectural Decay and Sustainability of Software Systems by Duc Minh Le, Carlos Carrillo, Rafael Capilla, and Nenad Medvidovic
Improving the Design of Existing Code by Martin Fowler.
Detecting Software Modularity Violations by Sunny Wong, Yuanfang Cai, Miryung Kim, and Michael Dalton
Detecting Architecturally-Relevant Code Smells in Evolving Software Systems by Isela Macia Bertran
Technology budgets: From value preservation to value creation by Deloitte Insights.
Written By

More By The Author
More In Software Architecture
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedMore In Software Architecture
Get updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed