Combining Security and Velocity in a Continuous-Integration Pipeline for Large Teams

How do you balance security and velocity in large teams? This question surfaced during my recent work with a customer that had more than 10 teams using a Scaled Agile Framework (SAFe), which is an agile software development methodology. In aiming for correctness and security of product, as well as for development speed, teams faced tension in their objectives. One such instance involved the development of a continuous-integration (CI) pipeline. Developers wanted to develop features and deploy to production, deferring non-critical bugs as technical debt, whereas cyber engineers wanted compliant software by having the pipeline fail on any security requirement that was not met. In this blog post, I explore how our team managed—and eventually resolved—the two competing forces of developer velocity and cybersecurity enforcement by implementing DevSecOps practices .
At the beginning of the project, I observed that the speed of developing new features was of highest precedence: each unit of work was assigned points based on the number of days it took to finish, and points were tracked weekly by product owners. To accomplish the unit of work by the deadline, developers made tradeoffs in deferring certain software-design decisions as backlog issues or technical debt to push features into production. Cyber operators, however, sought full compliance of the software with the project’s security policies before it was pushed to production. These operators, as a previous post explained, sought to enforce a DevSecOps principle of alerting “someone to a problem as early in the automated-delivery process as possible so that that person [could] intervene and resolve the issues with the automated processes.” These conflicting objectives were sometimes resolved by either sacrificing developer velocity in favor of security-policy enforcement or bypassing security policies to enable faster development.
In addition to maintaining velocity and security, there were other minor hurdles that contributed to the problem of balancing developer velocity with cybersecurity enforcement. The customer had developers with varying degrees of experience in secure-coding practices. Various security tools were available but not frequently used since they were behind separate portals with different passwords and policies. Staff turnover was such that employees who left did not share the knowledge with new hires, which caused gaps in the understanding of certain software systems, thereby increased the risk in deploying new software. I worked with the customer to develop two strategies to remedy these problems: adoption of DevSecOps practices and tools that implemented cyber policies in an automated way.
Adopting DevSecOps
A continuous integration pipeline had been partly implemented before I joined the project. It included a pipeline with some automated tests in place. Deployment was a manual process, projects had varying implementations of tests, and review of security practices was deferred as a task item just before a major release. Until recently, the team relied on developers to have secure-coding expertise, but there was no way to enforce this on the codebase other than through peer review. Some automated tools were available for developer use, but they required logging in to an external portal and running tests manually there, so these tools were used infrequently. Automating the enforcement mechanism for security policies (following the DevSecOps model) shortened the feedback loop that developers received after running their builds, which allowed for more rapid, iterative development. Our team created a standard template that could be easily shared among all teams so it could be included as part of their automated builds.
The standard template prescribed the tests that implemented the program’s cyber policy. Each policy corresponded to an individual test, which ran every time a code contributor pushed to the codebase. These tests included the following:
- Container scanning—Since containers were used to package and deploy applications, it was necessary to determine whether any layers of the imported image had existing security vulnerabilities.
- Static application testing—This type of testing helped prevent pushing code with high cyclomatic complexity and was vulnerable to buffer-overflow attacks, or other common programming mistakes that introduce vulnerabilities.
- Dependency scanning— After the Solar Winds attack, greater emphasis has been put on securing the software supply chain. Dependency scanning looks at imported libraires to detect any existing vulnerabilities in them.
- Secret detection—A test that alerts developers of any token, credentials, or passwords they could have introduced into the codebase, thereby compromising the security of the project.
There are several advantages to having an individual policy run on separate stages, which go back to historical best practices in software engineering, e.g., expressed in the Unix philosophy, agile software methodologies, and many seminal works. These include modularity, chaining, and standard interfaces:
- Individual stages on a pipeline executing a unique policy provide modularity so that each policy can be developed, changed, and expanded on without affecting other stages (the term “orthogonality” is sometimes used). This modularity is a key attribute in enabling refactoring.
- Individual stages also allow for chaining workflows, whereby a stage that produces an artifact can take in that artifact as its input and produce a new output. This pattern is clearly seen in Unix programs based on pipes and filters, where a program takes the output of another program as its input and create new workflows thereafter.
- Making each policy into its own stage also allows for clear distinction of software layers through standard interfaces, where a security operator could look at a stage, see if it passed, and perhaps change a configuration file without having to delve into the internals of the software implementing the stage.
These three key attributes resolved the issue of having multiple team members coding and refactoring security policies without a long onboarding process. It meant security scans were always run as part of the build process and developers didn’t have to remember to go to different portals and execute on-demand scans. The approach also opened up the possibility for chaining stages since the artifact of one job could be passed on to the next.
In one instance, a build job created an image tag that changed depending on the kind of branch on which it was being deployed. The tag was saved as an artifact and passed along to the next stage: container scanning. This stage required the correct image tag to perform the scanning. If the wrong tag was provided, the job would fail. Since the tag name could change depending on the build job, it could not work as a global variable. By passing the tag along as an artifact, however, the container-scanning stage was guaranteed to use the right tag. You can see a diagram of this flow below:
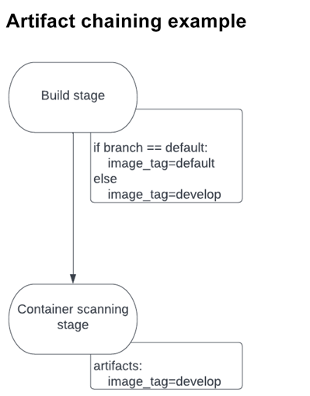
Declarative Security Policies
In certain situations, there are multiple advantages to using declarative rather than imperative coding practices. Instead of knowing how something is implemented, declarative expressions show the what. By using commercial tools we can specify a configuration file with the popular YAML language. The pipeline takes care of running the builds while the configuration file indicates what test to run (with what parameters). In this way, developers don’t have to worry about the specifics of how the pipeline works but only about the tests they wish to run, which corresponds with the modularity, chaining, and interface attributes described previously. An example stage is shown below:
container_scanning:
docker_img: example-registry.com/my-project:latest
include:
- container_scanning.yaml
The file defines a container_scanning stage, which scans a Docker image and determines whether there are any known vulnerabilities for it (through the use of open-source vulnerability trackers). The Docker image is defined in the stage, which can be an image in a local or remote repository. The actual details of how the container_scanning stage works is in the container_scanning.yaml file. By abstracting the functionality of this stage away from the main configuration file, we make the configuration modular, chainable, and easier to understand—conforming to the principles previously discussed.
Rollout and Learnings
We tested our DevSecOps implementation by having two teams use the template in their projects and test whether security artifacts were being generated as expected. From this initial batch, we found that (1) this standard template approach worked and (2) teams could independently take the template and make minor adjustments to their projects as necessary. We next rolled out the template for the rest of the teams to implement in their projects.
After we rolled out the template to all teams, I realized that any changes to the template meant that every team would have to implement the changes themselves, which incurred inefficient and unnecessary work (on top of the features that teams were working to develop). To avoid this extra work, the standard security template could be included as a dependency on their own project template (like code libraries are imported on files) using Yaml’s include command. This approach allowed developers to pass down project-specific configurations as variables, which would be handled by the template. It also allowed those developing the standard template to make necessary changes in an orthogonal way, as below:
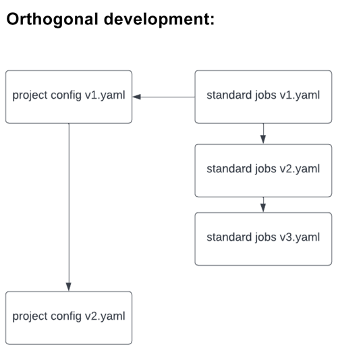
Outcome: A Better Understanding of Security Vulnerabilities
The implementation of DevSecOps principles into the pipeline enabled teams to have a better understanding of their security vulnerabilities, with guards in place to automatically enforce cyber policy. The automation of policy enabled a quick feedback loop for developers, which maintained their velocity and increased the compliance of written code. New members of the team quickly picked up on creating secure code by reusing the standard template, without having to know the internals of how these jobs work, thanks to the interface that abstracts away unnecessary implementation details. Velocity and security were therefore applied in an effective manner to a DevSecOps pipeline in a way that scales to multiple teams.
Additional Resources
Learn more about the SEI’s work in DevSecops - https://www.sei.cmu.edu/our-work/devsecops/
Read about the SEI blog post A Framework for DevSecOps Evolution and Achieving Continuous-Integration/Continuous-Delivery (CI/CD) Capabilities - https://insights.sei.cmu.edu/blog/a-framework-for-devsecops-evolution-and-achieving-continuous-integrationcontinuous-delivery-cicd-capabilities/
Learn more about the SCALED Agile Framework (SAFE) - https://www.scaledagileframework.com/
Written By

More By The Author
PUBLISHED IN
Get updates on our latest work.
Sign up to have the latest post sent to your inbox weekly.
Subscribe Get our RSS feedGet updates on our latest work.
Each week, our researchers write about the latest in software engineering, cybersecurity and artificial intelligence. Sign up to get the latest post sent to your inbox the day it's published.
Subscribe Get our RSS feed